1.什么是storm
Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有较高的吞吐率和较低的延迟。Storm是无状态的,它通过Apache ZooKeeper 管理分布式环境和集群状态。部署和开发Storm任务比较简单,可以并行地对实时数据执行各种操作。
由于Storm是用Clojure语言开发的(Clojure也是一种运行在JVM虚拟机上的语言),但是这种语言入门门槛较高,因此想从源码层面学习Storm有较大的难度。阿里使用Java重写了Storm并做了一些改进,称为JStorm,但目前由于阿里实时计算转向Flink,JStorm也已不维护了。
2.storm 核心概念
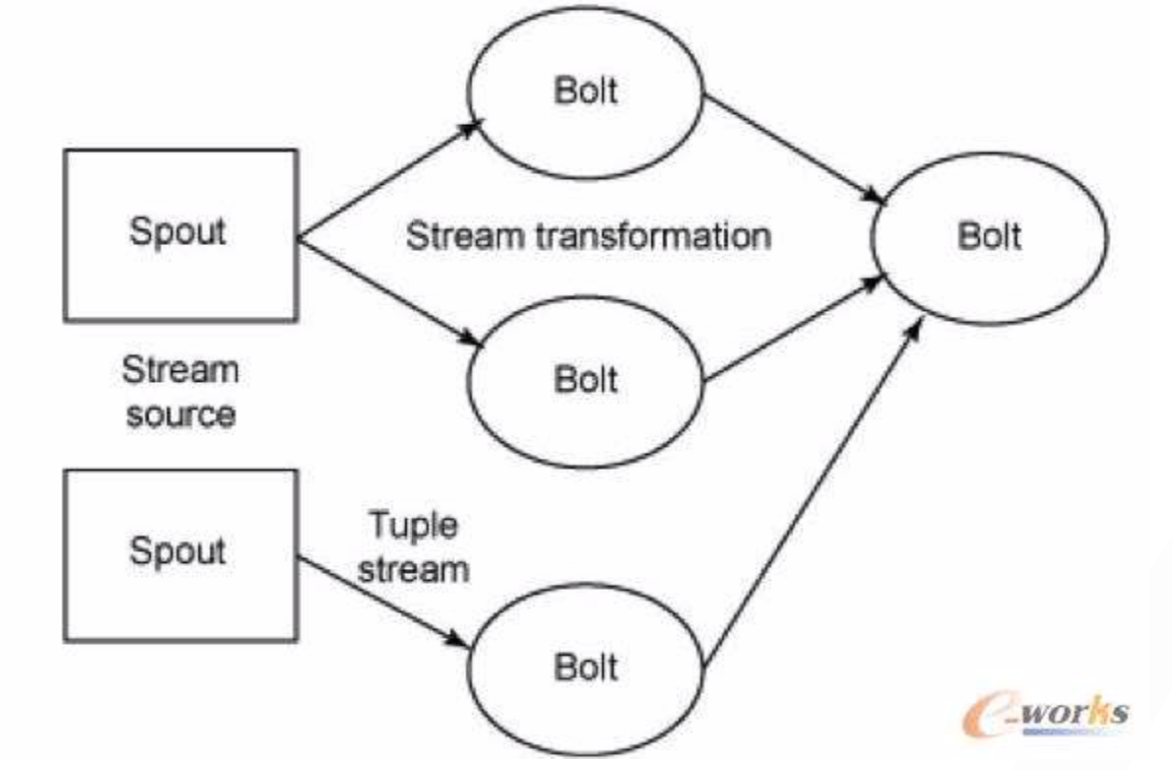
Tuple:是Storm中的主要数据结构。它是有序元素的列表。默认情况下, Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传 递到Storm集群。Tuple 可以理解为storm这个流中的数据。
Stream:是由Tuple组成的无序序列,也可以理解为数据流。
Spouts:数据流的源,也就是数据源。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列等)接受输入数据。你也可以编写spouts以从 数据源读取数据。“ISpout”是实现spouts的核心接口,一些特定的接 口是IRichSpout,BaseRichSpout,KafkaSpout等,是一些你可以直接使用的,现成的Spout。
Bolts:是逻辑处理单元。Spouts将数据传递到Bolts,经过处理产生新 的输出流。Bolts可以执行过滤,聚合,连接,与数据源和数据库交互 等操作。Bolts接收数据并发射到一个或多个Bolts。“IBolt”是实现 Bolts的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。
Topology:也称拓扑。Spouts和Bolts连接在一起,形成拓扑结构。实 时应用程序逻辑在拓扑中指定。简单地说,拓扑是有向图,其中顶点是 计算,边缘是数据流。拓扑从Spouts开始,Spouts将数据发射到一个或 多个Bolts。Bolt表示拓扑中具有最小处理逻辑的节点,并且Bolts的输 出可以发射到另一个Bolt作为输入。Storm保持拓扑始终运行,直到手 动终止拓扑。
Stream groupings:流分组。数据流从Spouts流到Bolts,或从一个 Bolt流到另一个Bolt。流分组控制元组在拓扑中的路由方式,并帮助我 们了解拓扑中的元组流。在当前版本中有8种流分组(另外也可以自定 义):Shuffle grouping(随机)、Fields grouping(按字段分组)、 Partial Key grouping(带负载均衡的按字段分组)、All grouping(复制给所有Bolts的Tasks)、Global grouping(传给一个 Bolt的Tasks)、None grouping(不关心如何分组)、Direct grouping(由tuple的生成者决定发送给哪个Task)、Local or shuffle grouping(若目标Bolt有多个worker进程,会发送给这些进程 的Tasks;否则执行Shuffle grouping)
3.storm 集群架构
Apache Storm的主要亮点是,它是一个容错,快速,无单点故障的分布式系统。我们可以根据需要在多个节点上安装Apache Storm,以增加集群的容量。下图描述了Apache Storm集群设计:
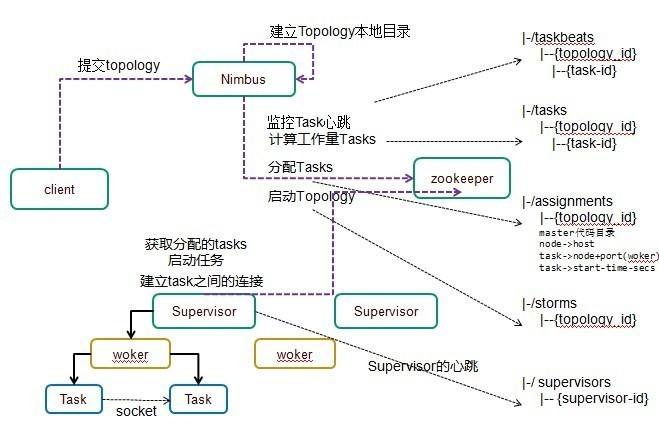
Apache Storm有两种类型的节点,Nimbus(主节点)和Supervisor(工作节点)。Nimbus是Apache Storm的核心组件。Nimbus的主要工作是运行Storm拓扑。Nimbus分析拓扑并收集要执行的任务。然后,它将任务分配给可用的Supervisor。
Supervisor将有一个或多个工作进程。Supervisor将任务委派给工作进程。工作进程将根据需要产生尽可能多的执行器并运行任务。Storm使用内部分布式消息传递系统来进行Nimbus和管理程序之间的通信。
Nimbus(主节点):Nimbus是Storm集群的主节点,负责在所有工作节点之间分发数据,向工作节点分配任务和监视故障。
Supervisor(工作节点):执行指令的节点被称为Supervisors。 Supervisor有多个工作进程,它管理工作进程以完成由nimbus分配的任务。
Worker process(工作进程):工作进程将执行与特定拓扑相关的任务。工作进程不会自己运行任务,而是创建执行器并要求他们执行特定的任务。工作进程将有多个执行器。
Executor(执行器):执行器是工作进程产生的单个线程。执行器运行一个或多个任务,但仅用于特定的Spout或Bolt。
Task(任务):任务执行实际的数据处理。所以,它是一个Spout或 Bolt。
ZooKeeper:Apache ZooKeeper是一种分布式一致性服务。Nimbus是无状态的,它依赖于ZooKeeper来监视工作节点的状态。ZooKeeper帮助 Supervisor与Nimbus交互。它负责维持Nimbus,Supervisor的状态。
4.storm 工作机制
最初,nimbus将等待Storm拓扑提交。
一旦提交拓扑,它将处理拓扑并收集要执行的所有任务和任务将被执行的顺序。
然后,nimbus将任务均匀分配给所有可用的supervisors。
在特定的时间间隔,所有supervisor将向nimbus发送心跳以通知它们仍然运行着。
当supervisor终止并且不向nimbus发送心跳时,则nimbus将任务分配给另一个supervisor。
当nimbus本身终止时,supervisor将在没有任何问题的情况下对已经分 配的任务进行工作。
一旦所有的任务都完成后,supervisor将等待新的任务分配。
终止的nimbus将由服务监控工具自动重新启动。
重新启动的拓扑将从停止的地方继续。同样,终止的supervisor也可以自动重新启动。由于nimbus和supervisor都可以自动重新启动,并且两者将像以前一样继续,因此Storm保证至少处理所有任务一次。
一旦处理了所有拓扑,则nimbus等待新的拓扑到达,并且类似地,supervisor等待新的任务。
5.storm 的 acker机制
Storm能够保证每一个由Spout发送的消息都能够得到完整地处理。这是由以下机制保证的。
Storm 的拓扑有一些特殊的称为“acker”的任务,这些任务负责跟踪 每个Spout发出的tuple的DAG。当一个acker发现一个DAG结束了,它就会给创建spout tuple的Spout任务发送一条消息,让这个任务来应答这个消息。你可以使用Config.TOPOLOGY_ACKER_EXECUTORS来配置拓扑的 acker数量。Storm默认会将acker的数量设置为每worker 1个任务。
当一个tuple在拓扑中被创建出来的时候——不管是在Spout中还是在 Bolt中创建的——这个tuple都会被配置一个随机的64位id。acker就是使用这些id来跟踪每个spout tuple的tuple DAG的。
Spout tuple的tuple树中的每个tuple都知道spout tuple的id。当你在 bolt中发送一个新tuple的时候,输入tuple中的所有spout tuple的id 都会被复制到新的tuple中。在tuple被ack的时候,它会通过回掉函数 向合适的acker发送一条消息,这条消息显示了tuple树中发生的变化。 也就是说,它会告诉acker这样一条消息:“在这个tuple树中,我的处 理已经结束了,接下来这个就是被我标记的新tuple”。
以下图为例,如果D tuple和E tuple是由C tuple 创建的,那么在C应 答的时候 tuple树就会发生变化:
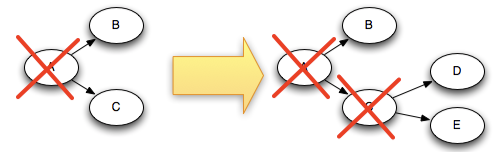
Acker实际上并不会直接跟踪tuple树。对于一棵包含数万个tuple节点 的树,如果直接跟踪其中的每个tuple,显然会很快把这个acker的内存 撑爆。所以,这里acker使用一个特殊的策略来实现跟踪的功能,使用 这个方法对于每个 spout tuple只需要占用固定的内存空间(大约20字 节)。这个跟踪算法是Storm 运行的关键,也是Storm的一个突破性技 术。
在acker任务中储存了一个表,用于将spout tuple的id和一对值相映射。 其中第一个值是创建这个tuple的任务id,这个id主要用于在后续操作 中发送结束消息。第二个值是一个64比特的数字,称为“应答值”(ack val)。这个应答值是整个tuple树的一个完整的状态表述, 而且它与树的大小无关。因为这个值仅仅是这棵树中所有被创建的或者 被应答的tuple的tuple id进行异或运算的结果值。
当一个acker任务观察到“应答值”变为0的时候,它就知道这个tuple 树已经完成处理了。因为tuple id实际上是随机生成的64比特数值,所 以“应答值”碰巧为0是一种极小概率的事件。理论计算得以得出,在每秒应答一万次的情况下,需要5000万年才会发生一次错误。而且即使 是这样,也仅仅会在tuple碰巧在拓扑中失败的时候才会发生数据丢失 的情况。
6.storm的安装
6.1.环境
操作系统centos 6.8
| 主机名 | IP地址 | 角色 | |||
| Zookeeper | Nimbus | Supervisor | RDPC | ||
| C6-node1 | 192.168.28.61 | 部署 | 部署 | 部署 | |
| C6-node2 | 192.168.28.62 | 部署 | 部署 | ||
| C6-node3 | 192.168.28.63 | 部署 | 部署 | ||
6.2.准备工作
1、修改hosts文件
# vim /etc/hosts 192.168.28.61 c6-node1.fblinux.com c6-node1 192.168.28.62 c6-node2.fblinux.com c6-node2 192.168.28.63 c6-node3.fblinux.com c6-node3
2、关闭防火墙和iptables
3、时间同步
4、安装JDK 1.8
yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel
5、安装zookeeper 集群
6.3.Storm集群搭建
如下配置在所有节点操作
1、下载安装
wget http://mirror.bit.edu.cn/apache/storm/apache-storm-1.2.1/apache-storm-1.2.1.tar.gz tar xf apache-storm-1.2.1.tar.gz -C /opt/ cd /opt/ ln -s apache-storm-1.2.1/ storm
2、设置环境变量
# vim /etc/profile export STORM_HOME=/opt/storm export PATH=$PATH:$STORM_HOME/bin # source /etc/profile
3、修改配置文件
# cat /opt/storm/conf/storm.yaml
storm.zookeeper.servers:
- "c6-node1"
- "c6-node2"
- "c6-node3"
storm.local.dir: "/opt/storm/data/"
nimbus.seeds: ["c6-node1"]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4、创建数据目录
# mkdir /opt/storm/data/
5、启动storm守护进程
c6-node1运行
# /opt/storm/bin/storm nimbus & # /opt/storm/bin/storm ui &
c6-node2/3 运行
# /opt/storm/bin/storm supervisor &
6、启动后验证
[root@c6-node1 ~]# jps 26277 core # ui 进程 26054 nimbus 1883 QuorumPeerMain # zookeeper进程 26427 Jps [root@c6-node2 ~]# jps 1847 QuorumPeerMain 3034 Jps 2875 Supervisor [root@c6-node3 ~]# jps 2096 QuorumPeerMain 6489 Jps 6300 Supervisor
访问ui

7.storm配置
Storm全部可配置的参数可以在Storm源码的conf/defaults.yaml下看到 (https://github.com/apache/storm/blob/v1.2.1/conf/defaults.yaml), 你可以在刚才我们修改的storm.yaml中覆盖其默认值,也可以在内部组件 (覆盖spout或bolt的getComponentConfiguration实现)或外部组件(对 TopologyBuilder的setSpout或setBolt方法的返回对象调用 addConfiguration或addConfigurations)的编码中覆盖其默认值,其优 先级顺序如下:
defaults.yaml < storm.yaml < 内部组件定义的配置 < 外部组件定义的配置
重点配置讲解如下:
storm.zookeeper.servers:Storm连接的Zookeeper节点主机名或IP,可填写多个,见前面例子
storm.zookeeper.port:Zookeeper对外提供服务的端口号,默认2181 storm.zookeeper.root Storm在Zookeeper上使用的根节点名,默认”/ storm”,可按需修改。
storm.cluster.mode:Storm集群的默认工作模式,默认为”distributed”, 另一个可选值为”local”,没有特殊原因不需要修改。
nimbus.seeds:nimbus节点列表,默认为[“localhost”],可通过逗号分 隔指定多个节点,以便进行HA。
nimbus.supervisor.timeout.secs:supervisor发送给nimbus的心跳的超 时时间,默认60,即nimbus超过60s未收到某supervisor的心跳即认为其 已死亡,不会再向其分配任务。调小该值可以更快的检测到节点异常,但也增大了由于网络抖动等情况误判的风险。
ui.host:Storm监控页面绑定的地址,默认任何IP都可以访问。
ui.port:Storm监控页面使用的端口号,默认8080,如本机8080端口被占 用,可指定一个其他的端口号。
logviewer.port:Storm的日志浏览服务的端口号,默认8000,按需修改。 drpc.port Storm的DRPC服务的端口号,默认3772,DRPC是为了实现基于 Storm的分布式RPC而提供的一种服务,启动DRPC服务端后即可调用其API。
supervisor.slots.ports:定义在本节点上可运行多少个workers,每个 worker使用其中的一个端口进行通信。默认为6700、6701、6702、6703四 个端口,可按需增加。
supervisor.memory.capacity.mb:定义supervisor节点上有多少内存可 被Storm所用,默认3072.0即3GB,如果节点为Storm集群专用,则设置为 比总物理内存数略小即可。
supervisor.cpu.capacity:定义supervisor节点上有多少CPU核可被 Storm所用,默认400.0即为4个核,如果节点为Storm集群专用,则可以设置为总核数。
worker.heap.memory.mb:定义task的worker所使用的堆内存数,默认768。
topology.workers:每个topology运行时worker的默认数目,即整个集群 中参与该topology运算的进程数,默认值为1,通常会在代码中覆盖该值。 topology.acker.executors topology的acker数,我们在前一讲已经介 绍了acker的作用,默认值null代表本参数的值设定为和 topology.workers一致,如果改为0,则表示默认不启用acker机制,但一 般在集群层面不会覆盖默认值。
topology.max.task.parallelism:topology的最大并行度,即运行该 topology的worker的总线程数,默认为null表示不限制,需要限制的话可 以在代码中覆盖。
topology.max.spout.pending:一个spout task中可处于pending状态的 最大tuple数量,通过设置该值,可以起到流控的作用,如果数据输入速 度快于storm处理速度,则达到该限制时就不会再获取数据源的数据,注意这是“一个”spout的限制而并非全部spouts。默认为null即不加限制。
8.storm 日常维护
8.1.常用命令
可使用storm命令将topology提交到集群,需要指定jar包的路径(如 path/to/allmycode.jar),要运行的类名(如org.me.MyTopology), 以及所使用的参数:
storm jar path/to/allmycode.jar org.me.MyTopology arg1 arg2 arg3
要杀掉一个topology,需要提供提交topology时拿到的名称,执行: storm kill {stormname} [-w wait-time-secs]
Storm不会立即杀死 topology,相反,它会停用所有的端口,以使它们不 再发出任何tuple,然后Storm会在销毁所有workers之前等待Config. TOPOLOGY_MESSAGE_TIMEOUT_SECS秒(也可通过以上命令的-w参数设置)。 这给了topology足够的时间来完成它被杀死时处理的任何tuple。
启动DRPC守护进程:
storm drpc
启动日志浏览服务:
storm logviewer
列出正在运行的topology及其状态:
storm list
动态调整topology的worker数和某组件的并行度:
storm rebalance topology-name [-w wait-time-secs] [-n new-num- workers] [-e component=parallelist] -w参数指定等待的时间。
-n参数用于为topology设置新的worker数。-e参 数用于为一个spout或bolt设置新的并行度(线程数),但该数值只能在 当前基础上改小,而不能改大。
8.2.进程管理
由于Storm是一个快速失败的系统,需要用某些工具 来监控nimbus、supervisor(这里是指storm的工作节点)的活性,推荐使用supervisor(Python开发的进程管理工具)。
如果nimbus、supervisor频繁挂掉,需要从根本上解决其问题,通常都 是由于OOM或某种特定异常导致的。
8.3.Pacemaker
Storm集群本身是无状态的,默认情况下其会将状态都保存在Zookeeper中。 随着Storm集群的扩大,大量worker心跳会写入Zookeeper,使得磁盘和网络开始成为瓶颈。 Pacemaker就是一个在这种情况下代替Zookeeper处理worker心跳的守护进 程,自1.0版本起开始提供。由于心跳数据是暂时的,不需要被持久化到磁盘中或者通过网络传输,完全可以在内存中储存和提供服务。 Pacemaker作为一个简单的基于内存的K/V存储,将类似Zookeeper节点的字符串作为键,一个字节数组作为值。
要使Pacemaker启动并运行, 请在所有节点上的集群配置中设置以下选项: storm.cluster.state.store: “org.apache.storm.pacemaker.pacemaker_state_factory”
还需要设置至少一个Pacemaker服务器(设置多个可以起到HA作用): pacemaker.servers:
– host1
– host2
然后启动所有的守护进程(包括 Pacemaker):
storm pacemaker
8.4.指标监控
Storm有一些指标值得监控,主要包括Storm守护进程中的rpc调用和http 任务。这些指标可以通过JMX或HTTP向外部报告。你可以使用JConsole或 VisualVM连接到相应的JVM进程并查看这些指标的统计。
要为Storm守护进程开启JMX统计,需要在storm.yaml中配置以下选项:
nimbus.childopts: "-Xmx1024m -Dcom.sun.management.jmxremote.local.only=false - Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=3333 - Dcom.sun.management.jmxremote.ssl=false - Dcom.sun.management.jmxremote.authenticate=false" ui.childopts: "-Xmx768m -Dcom.sun.management.jmxremote.port=3334 - Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote - Dcom.sun.management.jmxremote.ssl=false - Dcom.sun.management.jmxremote.authenticate=false” logviewer.childopts: "-Xmx128m -Dcom.sun.management.jmxremote.port=3335 - Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote - Dcom.sun.management.jmxremote.ssl=false - Dcom.sun.management.jmxremote.authenticate=false" drpc.childopts: "-Xmx768m -Dcom.sun.management.jmxremote.port=3336 - Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote - Dcom.sun.management.jmxremote.ssl=false - Dcom.sun.management.jmxremote.authenticate=false" supervisor.childopts: "-Xmx256m -Dcom.sun.management.jmxremote.port=3337 - Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote - Dcom.sun.management.jmxremote.ssl=false - Dcom.sun.management.jmxremote.authenticate=false"
转载请注明:西门飞冰的博客 » 实时计算——storm原理和运维