1.结论
hive 压缩和存储组合推荐使用:orc + snappy 获得最好的性能和合理的压缩率
1.1.存储格式选择
Hive支持的存储数据的格式主要有:textfile 、orc、parquet。
orc和parquet是基于列式存储的,orc存储格式占用空间比parquet要小,且orc格式查询性能普遍比parquet格式高出10%~20%,所以生产一般选择使用orc格式存储
Parquet 主要使用场景在 Impala 和 Hive 共享数据和元数据的场景,因为orc不支持impala引擎。
1.2.压缩算法的选择
计算过程中压缩算法的选择,就比较耿直和直接,绝大多数场景就是谁压缩/解压快选择谁,因为在计算过程中过度追求数据的压缩率,会增加压缩的时间和CPU的占用,反而得不偿失
snappy 是目前最稳定的压缩算法,具有高速的压缩解压速度和合理的压缩率
ZLIB 压缩算法虽然是orc存储默认的压缩算法,压缩率也比snappy要好,但是因为压缩解压缩速度比较慢,所以不建议使用。
2.文件存储格式
Hive支持的存储数据的格式主要有:textfile 、orc、parquet。
2.1.列式存储和行式存储

如图所示左边为逻辑表,右边第一个为行式存储(一行中的数据在存储介质中以连续存储形式存在),第二个为列式存储(一列中的数据在存储介质中以连续存储形式存在)。
1)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
行式存储的适用场景包括:
1、适合随机的增删改查操作;
2、需要在行中选取所有属性的查询操作;
3、需要频繁插入或更新的操作,其操作与索引和行的大小更为相关。
4、行式数据库主要适合于在线交易性的OLTP应用
2)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
列式存储的适用场景包括:
1、查询过程中,可针对各列的运算并发执行(SMP),在内存中聚合完整记录集,可降低查询响应时间;
2、可在数据列中高效查找数据,无需维护索引(任何列都能作为索引),查询过程中能够尽量减少无关IO,避免全表扫描;
3、因为各列独立存储,且数据类型已知,可以针对该列的数据类型、数据量大小等因素动态选择压缩算法,以提高物理存储利用率;如果某一行的某一列没有数据,那在列存储时,就可以不存储该列的值,这将比行式存储更节省空间。
4、列式数据库主要适合于海量静态数据的分析,一般应用于OLAP
textfile的存储格式都是基于行存储的。
orc和parquet是基于列式存储的
2.2.TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,Hive不会对数据进行切分,从而无法对数据进行并行操作。
2.3.Orc格式
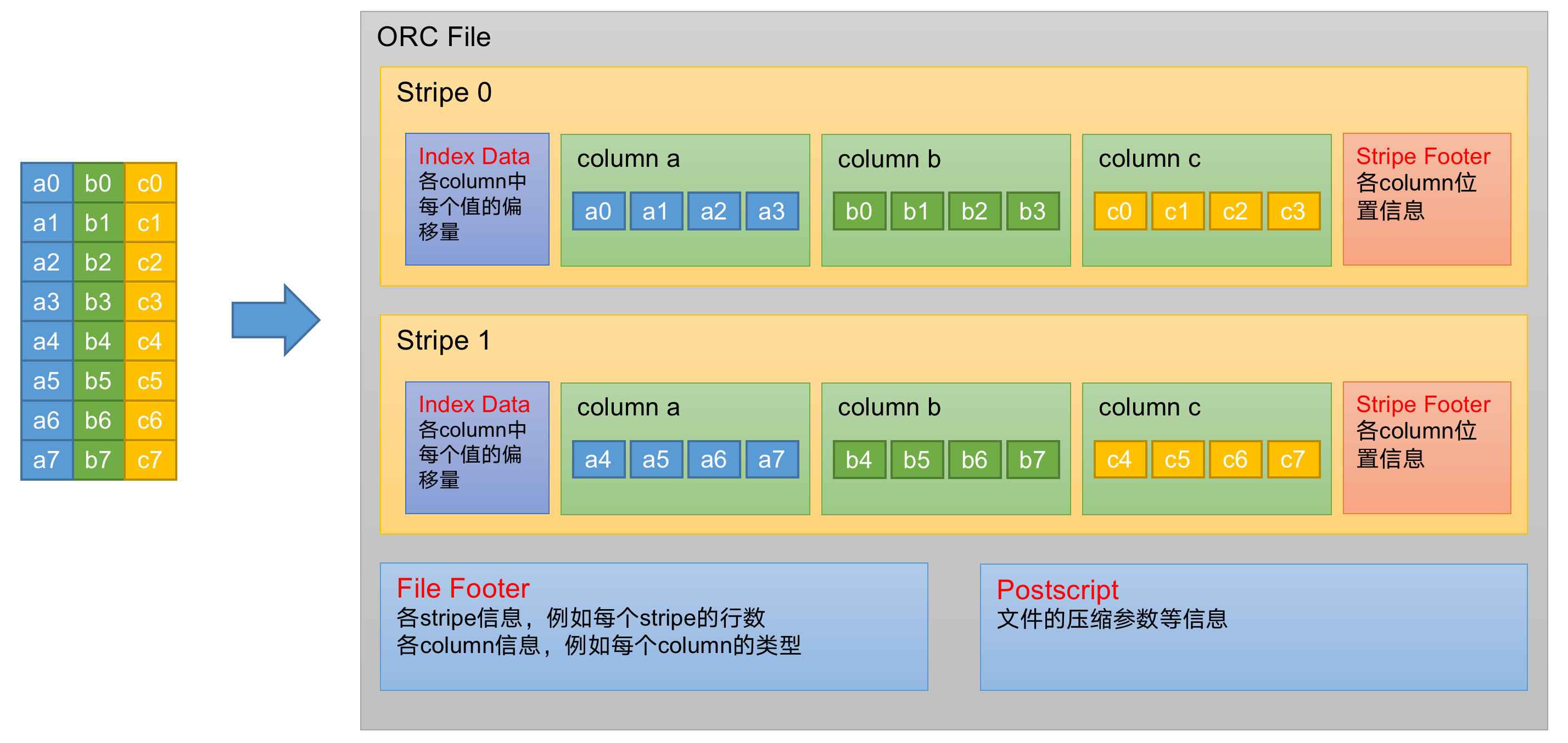
(1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
(2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
(3)Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
2.4.Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
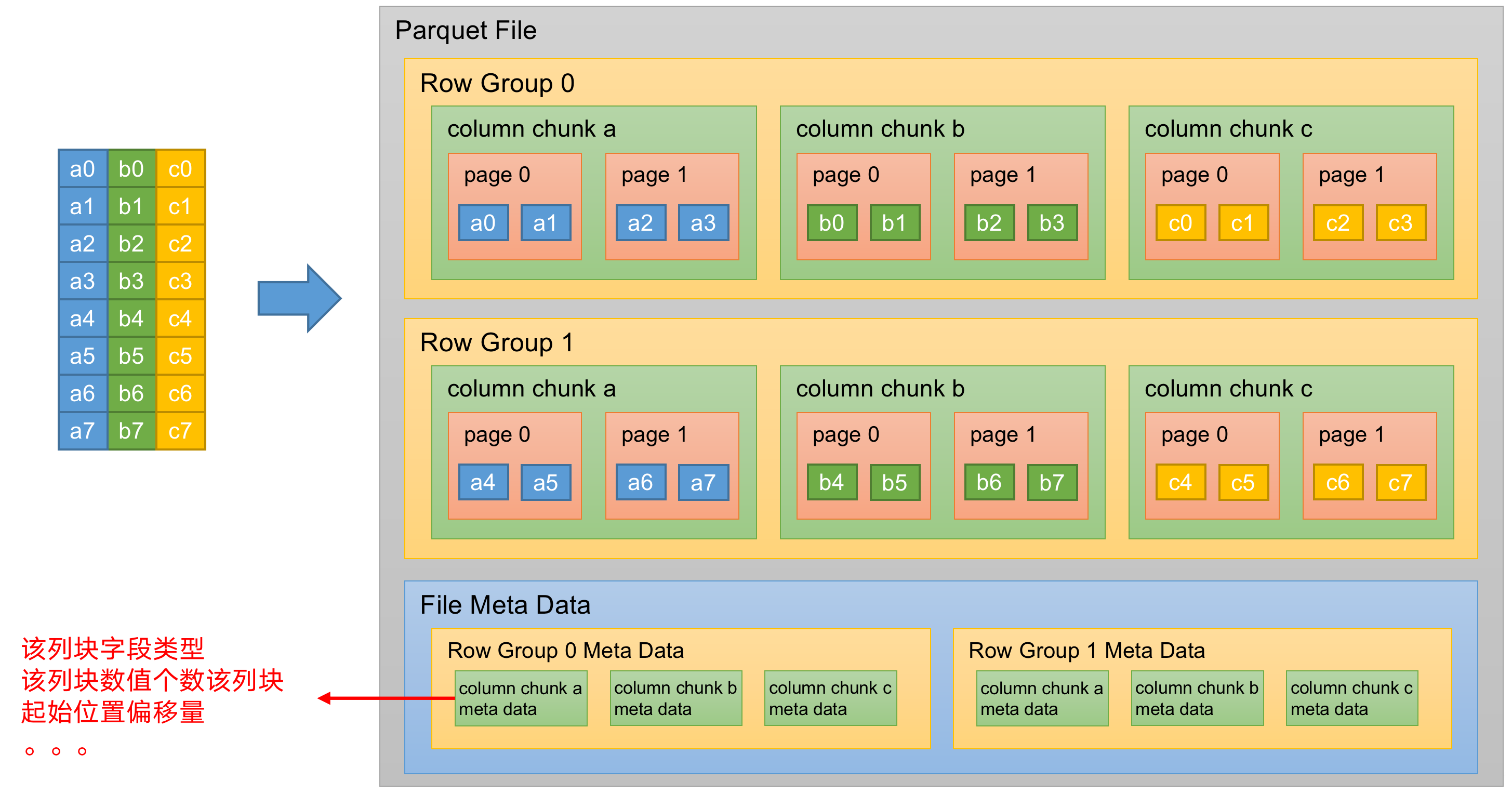
(2)列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照HDFS Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式。
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页
3.压缩算法
3.1.压缩的好处和坏处
压缩的优点:以减少磁盘IO、节省磁盘存储空间。由于压缩后的数据占用的带宽更少,因此可以加快数据在Hadoop集群流动的速度。
压缩的缺点:Hive做大数据分析运行过程中,需要花费额外的时间/CPU做压缩和解压缩计算。
4.压缩和存储组合使用
创建一个snappy压缩的ORC存储方式
hive (default)>
create table log_orc_snappy(
id string,
name string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
创建一个snappy压缩的parquet存储方式
create table log_parquet_snappy(
id string,
name string
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");
5.问题
网上描述:ORC文件支持Snappy压缩,但不支持lzo压缩,所以在实际生产中,使用Parquet存储 + lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。
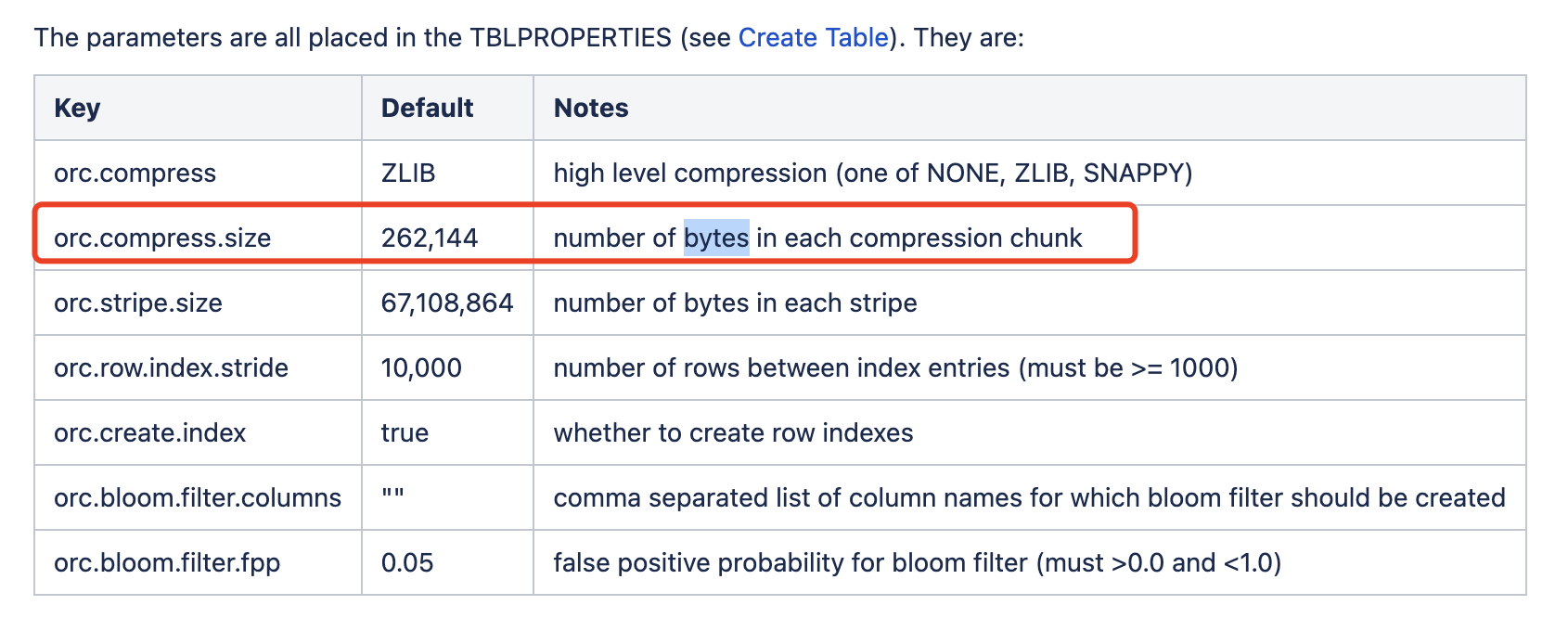
错误点:ORC+Snappy 不是对整体的数据集进行压缩,而是对ORC的每一个文件块进行压缩,所以不存在分割大文件的情况,具体可参考官方文档如下配置,默认262,144 bytes一个压缩块
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
转载请注明:西门飞冰的博客 » hive存储格式和压缩算法选择