为什么不能直接更新缓存
首先要做一个小科普,在日常开发中,无论使用进程内缓存(如:ehcache),还是进程外的缓存中间件(如:redis),他的本质就是利用内存的高吞吐的特性高效的完成数据的提取工作。因为底层mysql 在进行数据提取操作的时候是随机读写,性能比较慢。我们通常把热点数据放在内存缓存中来进行存储和提取。
应用程序一个基本的处理过程,首先是判断缓存中数据存不存在,如果存在直接从缓存中把数据提取出来就可以了;要是数据在缓存中不存在,就需要先去数据库查询,把数据提取出来,然后一边返回数据,一边把数据放入缓存中。这样第二次查询进来的时候,因为缓存中已经有数据了,所以就不用再向数据库查询数据了,通过缓存直接返回结果,就可以完成数据高效率的提取工作。这个就是缓存的一般性的处理过程。
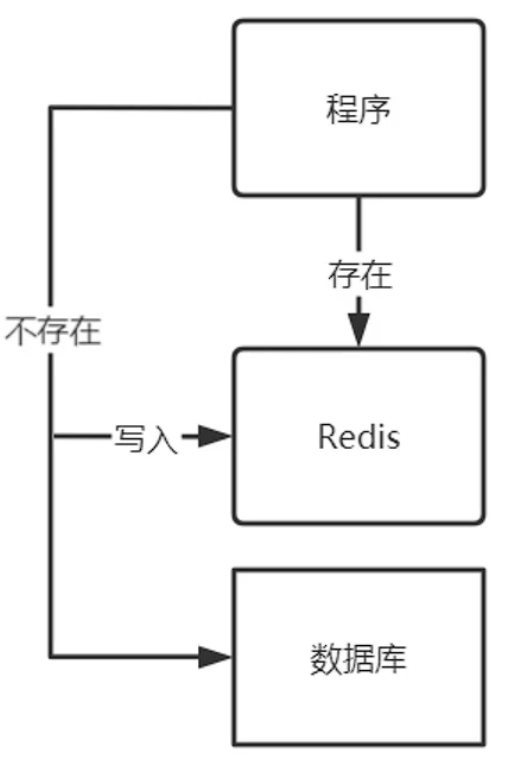
但是在我们处理过程中,要是数据有更新,缓存和数据库先更新哪个,后更新哪个,这个是有说法的。
盖棺定论一下,无论是redis还是ehcache这种缓存组件,都不要考虑去更新缓存。

为什么不要更新缓存,原因是有着并发性问题。
举例:有两个线程做着相同的事情,都是更新库和更新缓存操作,只不过是操作的值不一样,单独来看,两个操作都没有问题。但是我们在并发环境下使用,就有问题了。
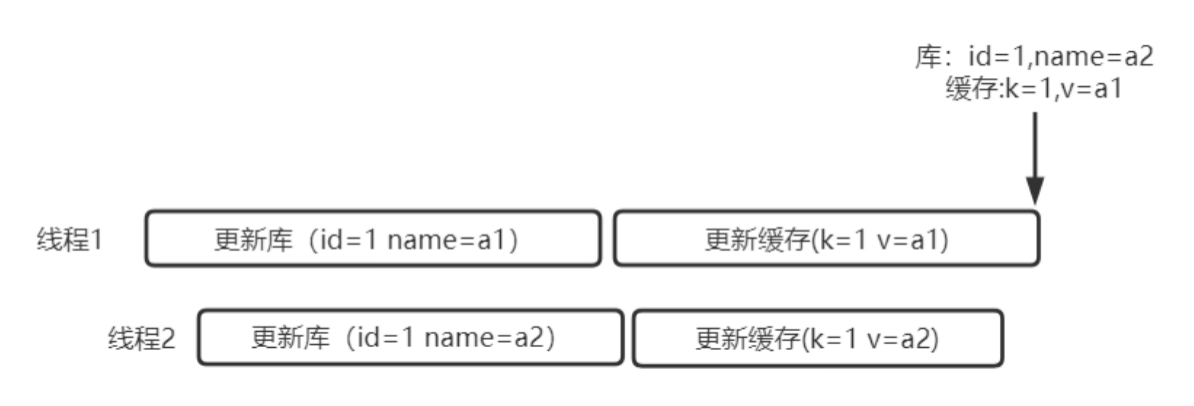
在数据库中我们线程1先更新了(id =1 name=a1),然后线程2又立刻更新了(id =1 name=a2),很明显name=a2会覆盖掉线程1操作的name=a1,因为a2是后完成的。但是由于各种原因,在我们JAVA程序中出现了一些延时,或者一些其他情况,我们线程2更新缓存的操作,会比线程1执行的更早,也就是线程1会把线程2处理的结果在缓存中覆盖掉。相当于在数据库层面,线程2的结果覆盖了线程1的结果,在缓存层面,线程1的结果覆盖了线程2的结果。
这就是典型的因为使用了更新缓存的操作,出现了数据不一致的情况。所以一定不要对缓存进行更新。
那不对缓存更新应该怎么做呢?这个时候Cache Aside Pattern就上场了。
Cache Aside Pattern是什么
Cache Aside Pattern是经典的缓存一致性处理模式,本质是“先写库,再删缓存”
为什么不是”先删缓存,再写库”
举例:线程1,将id=1的name字段值从a1更新为a2,线程1先删除缓存在更新库,这个单独线程处理没有任何问题。但是在并发环境下,在删完缓存的情况下,线程2进来了,线程2是一个查询的操作,线程2去查询缓存,发现缓存中没有数据,然后线程2去查询数据库,这个时候数据库还没有被线程1更新,线程2拿到的还是name=1的旧数据,然后线程2把name=1的数据写入到缓存中。这个时候线程1去更新数据库,就出现了缓存与数据库数据不一致的情况。
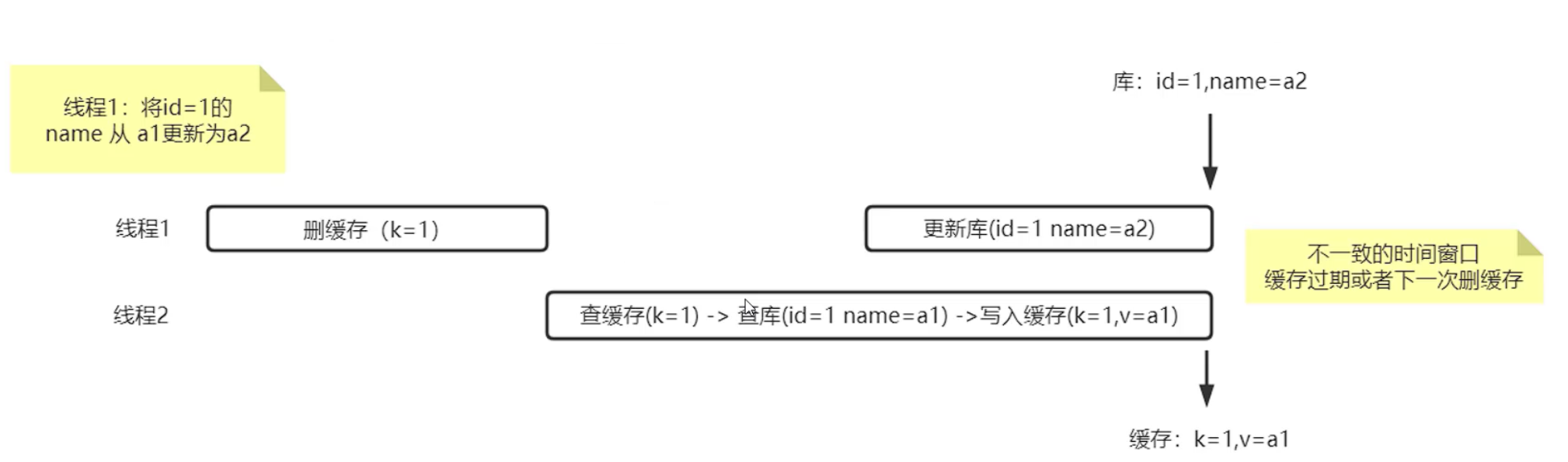
那么出现了数据库和缓存不一致的情况,这种不一致的时长会有多久呢?
第一种情况:根据设置的缓存时间决定,只有缓存过期以后,正确的数据才会被重新写入。
第二种情况:下一次删除缓存,正确的数据才可能会被写入
很明显,上面两种数据不一致的时间是不确定且不能接受的。
Cache Aside Pattern 理想流程
线程2:正常查询缓存(空),然后查询数据库,并写入缓存,这些都是正常完成的。但是在同步处理的过程中,线程1进行了更新的操作,不过更新使用了”Cache Aside Patten模型”,更新后增加了删除缓存的操作。删除缓存的时候,依旧有可能会出现并发性的问题,但是出现的时间极短。因为出现不一致的情况出现在:当线程2写入完成后和线程1删缓存这一段的时间区域里面,有线程来查询数据因为线程1还没有删除缓存所以会获取到旧的数据,不过时间极短。当线程1删除完成数据之后,问题就会立即解决。

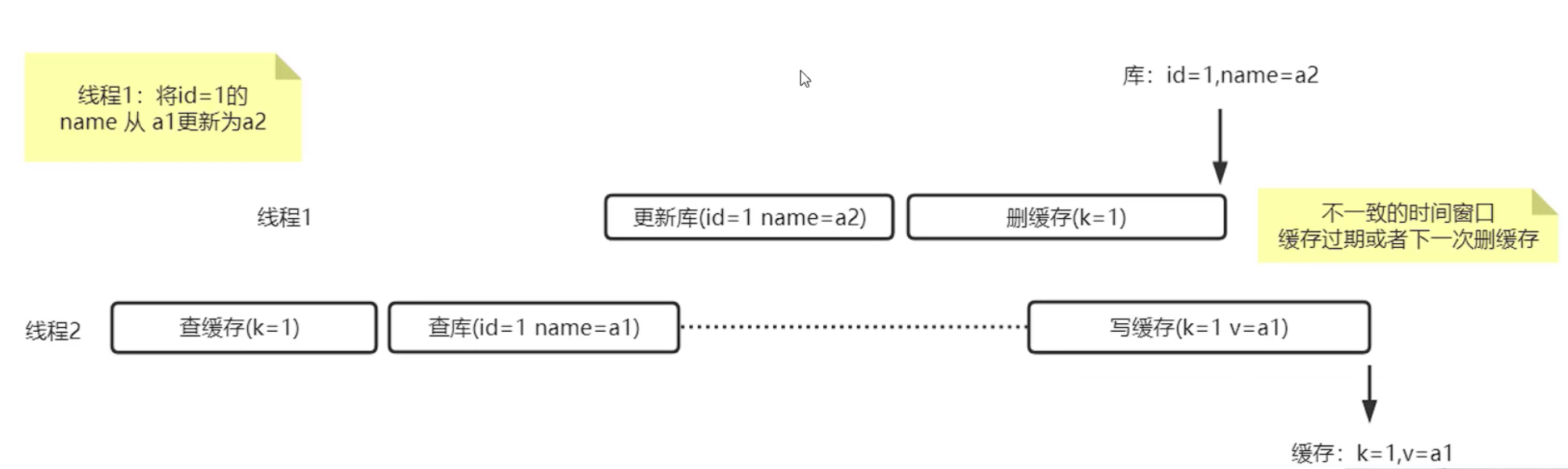
Cache Aside Pattern 极端流程
Cache Aside Pattern 极端情况的产生是在写缓存是在删缓存之后完成的。
举例:并发场景下,线程1先更新在删除,线程2是先查缓存在查库,但是线程2因为某一些问题,线程2的写缓存操作,是在线程1删缓存以后完成的,这个时候缓存里面还是旧的数据,就出现了缓存和数据库不一致的情况。
延迟双删
Cache Aside Pattern 极端情况是写缓存在删缓存之后完成的,所以写入缓存的数据是旧的,会出现缓存和数据库不一致的情况。
这个时候我们想个办法让删除缓存在写缓存之后完成不就行了吗。
所以我们增加了额外一个处理,我们删除缓存之后,事情不算完,我们通过定时任务或MQ消息队列发送延迟消息,比如说2秒钟之后再对同样的缓存进行删除,只要线程2的时间没有超过这2秒钟的话,那么就可以保证删缓存的操作,是在写缓存之后完成的。
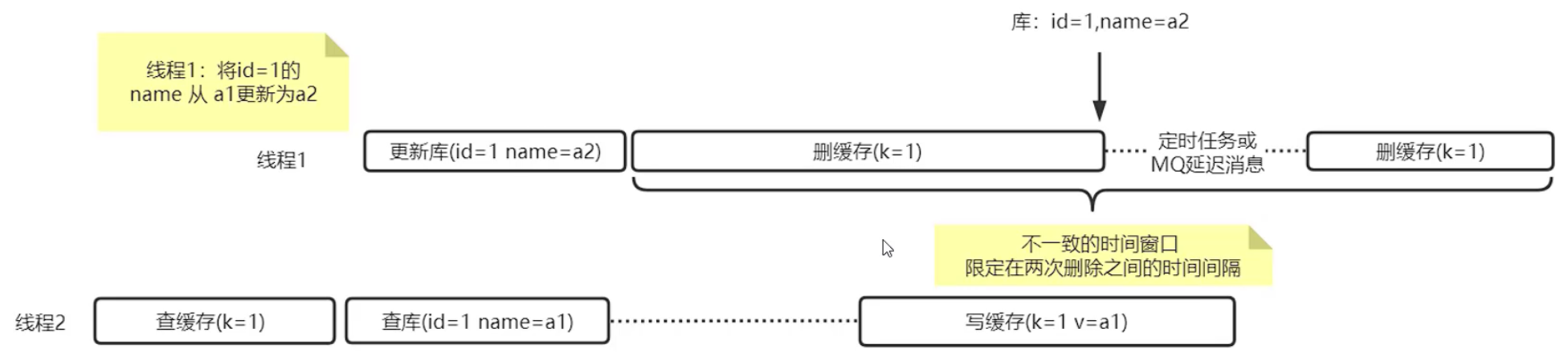
通过这种两次删除的处理,我们就把他称为延迟双删:他是解决互联网高并发下一个极端场景场景,写缓存是在删缓存之后的场景,我们就通过延迟任务来再次执行一下删缓存。
延迟的时间要设置多长,就决定我们不一致的时间窗口有多长,这个需要根据我们具体的业务场景来定。
说明
“Cache Aside Pattern+延迟双删除” 是一个无锁方案只能保证并发的前提下尽可能减少不一致的可能,这也是AP模式下BASE的一种技术,做不到数据的完全一致。
在一些极端情况下,必须要保证缓存与数据库强一致,最好的办法是分布式锁,这样并发性就完蛋了。而且增加缓存的目的就是为了增加系统的并发性能。
所以在大多数互联网项目中,都会采用AP的方案进行设计,采用AP的方案就无可避免的会出现数据不一致的情况,只是在不同的架构设计下,出现不一致的可能性有多有少
转载请注明:西门飞冰的博客 » 缓存一致性模式Cache Aside Pattern