1.Spark Shuffle的演进过程
Spark最初版本HashShuffle。
Spark 0.8.1版本以后优化后的HashShuffle。
Spark1.1版本加入SortShuffle,默认是HashShuffle。
Spark1.2版本默认是SortShuffle,但是可配置HashShuffle。
Spark2.0版本删除HashShuffle只有SortShuffle。
2.Shuffle的原理和执行过程
shuffle 过程中,各个节点上的相同 key 都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同 key。而且相同 key 都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的 key 过多,导致内存不够存放,进而溢写到磁盘文件中。因此在 shuffle 过程中,可能会发生大量的磁盘文件读写的 IO 操作,以及数据的网络传输操作。磁盘 IO 和网络数据传输也是 shuffle 性能较差的主要原因。
Shuffle一定会有落盘。
- 如果Shuffle过程中落盘数据量减少,那么可以提高性能。
- 算子如果存在预聚合功能,可以提高Shuffle的性能,比如reduceByKey
Shuffle的目的是为了给数据进行分组。上游的数据是乱序的,下游想通过某种规则将数据整合到一起,如奇偶数据分组,由于是分布式的原因,就需要用到Shuffle
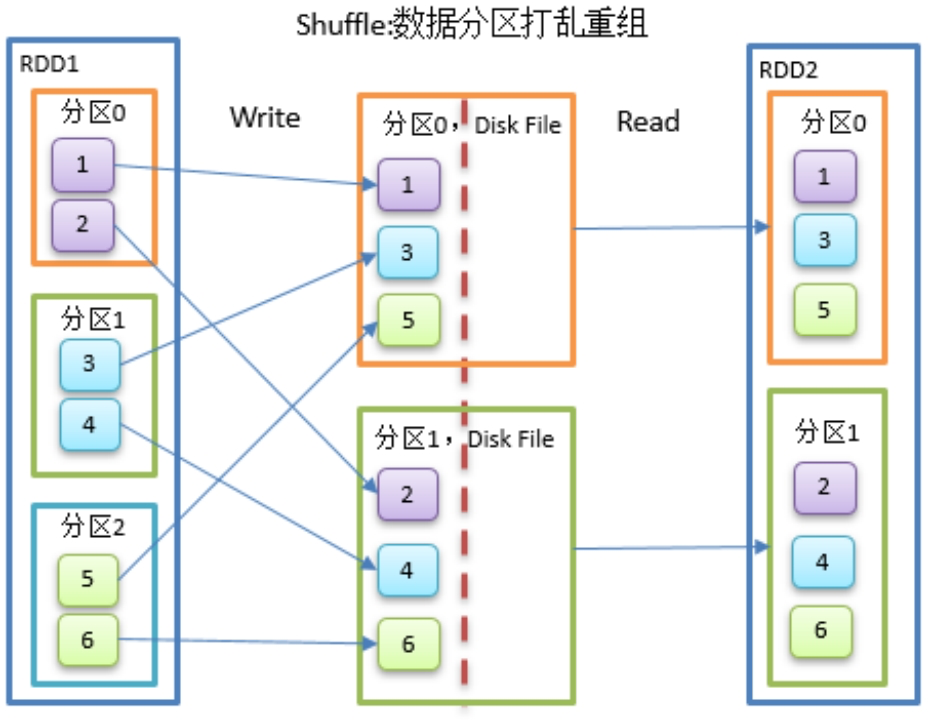
2.1.Shuffle中的任务个数
Spark Shuffle分为map阶段和reduce阶段,或者称之为ShuffleRead阶段和ShuffleWrite阶段,那么对于一次Shuffle,map过程和reduce过程都会由若干个task来执行,那么map task和reduce task的数量是如何确定的呢?
假设Spark任务从HDFS中读取数据,那么初始RDD分区个数由该文件的split个数决定,也就是一个split对应生成的RDD的一个partition,我们假设初始partition个数为N。
初始RDD经过一系列算子计算后(假设没有执行repartition和coalesce算子进行重分区,则分区个数不变,仍为N,如果经过重分区算子,那么分区个数变为M),我们假设分区个数不变,当执行到Shuffle操作时,map端的task个数和partition个数一致,即map task为N个。
reduce端的stage默认取spark.default.parallelism这个配置项的值作为分区数,如果没有配置,则以map端的最后一个RDD的分区数作为其分区数(也就是N),那么分区数就决定了reduce端的task的个数。
2.2.Reduce端数据的读取
根据stage的划分我们知道,map端task和reduce端task不在相同的stage中,map task位于ShuffleMapStage,reduce task位于ResultStage,map task会先执行,那么后执行的reduce task如何知道从哪里去拉取map task落盘后的数据呢?
reduce端的数据拉取过程如下:
1、map task 执行完毕后会将计算状态以及磁盘小文件位置等信息封装到MapStatus对象中,然后由本进程中的MapOutPutTrackerWorker对象将mapStatus对象发送给Driver进程的MapOutPutTrackerMaster对象;
2、在reduce task开始执行之前会先让本进程中的MapOutputTrackerWorker向Driver进程中的MapoutPutTrakcerMaster发动请求,请求磁盘小文件位置信息;
3、当所有的Map task执行完毕后,Driver进程中的MapOutPutTrackerMaster就掌握了所有的磁盘小文件的位置信息。此时MapOutPutTrackerMaster会告诉MapOutPutTrackerWorker磁盘小文件的位置信息;
4、完成之前的操作之后,由BlockTransforService去Executor0所在的节点拉数据,默认会启动五个子线程。每次拉取的数据量不能超过48M(reduce task每次最多拉取48M数据,将拉来的数据存储到Executor内存的20%内存中)。
3.HashShuffle解析(已废弃)
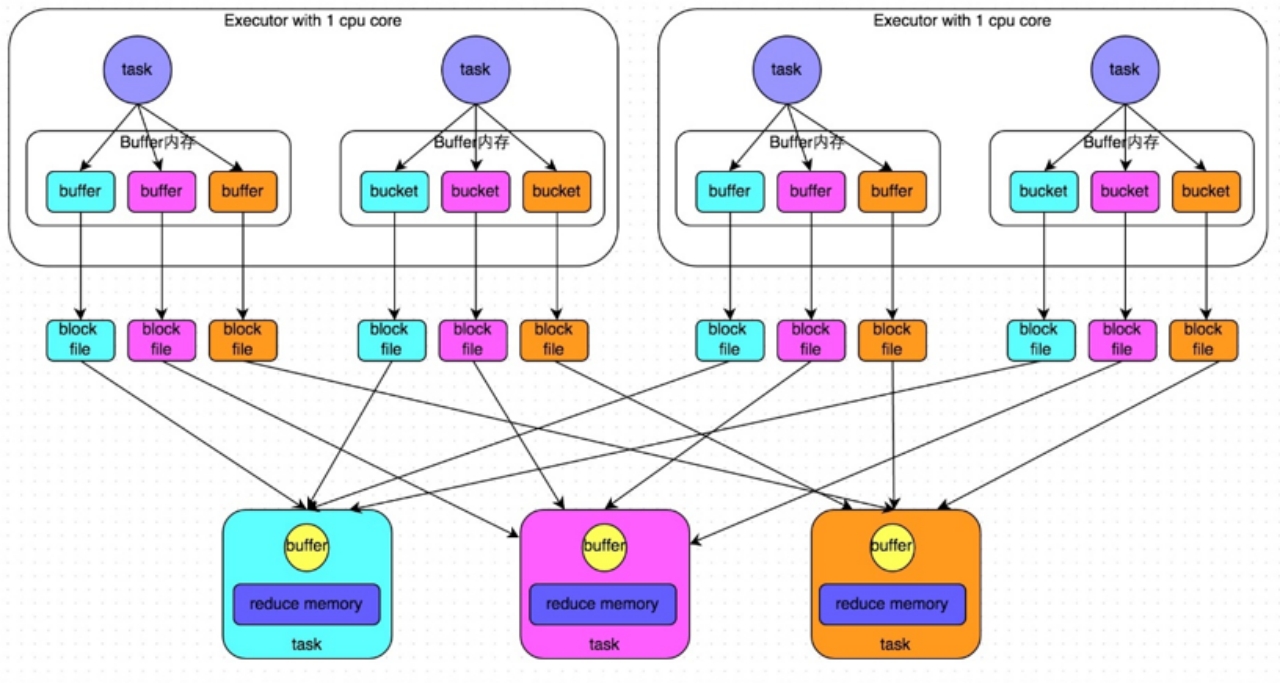
3.1.未优化的HashShuffle
缺点:中间小文件过多
shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“划分”。所谓“划分”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个task,总共有10个Executor,每个Executor执行5个task,那么每个Executor上总共就要创建500个磁盘文件,所有Executor上会创建5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
shuffle read阶段,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,map task给下游stage的每个reduce task都创建了一个磁盘文件,因此shuffle read的过程中,每个reduce task只要从上游stage的所有map task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
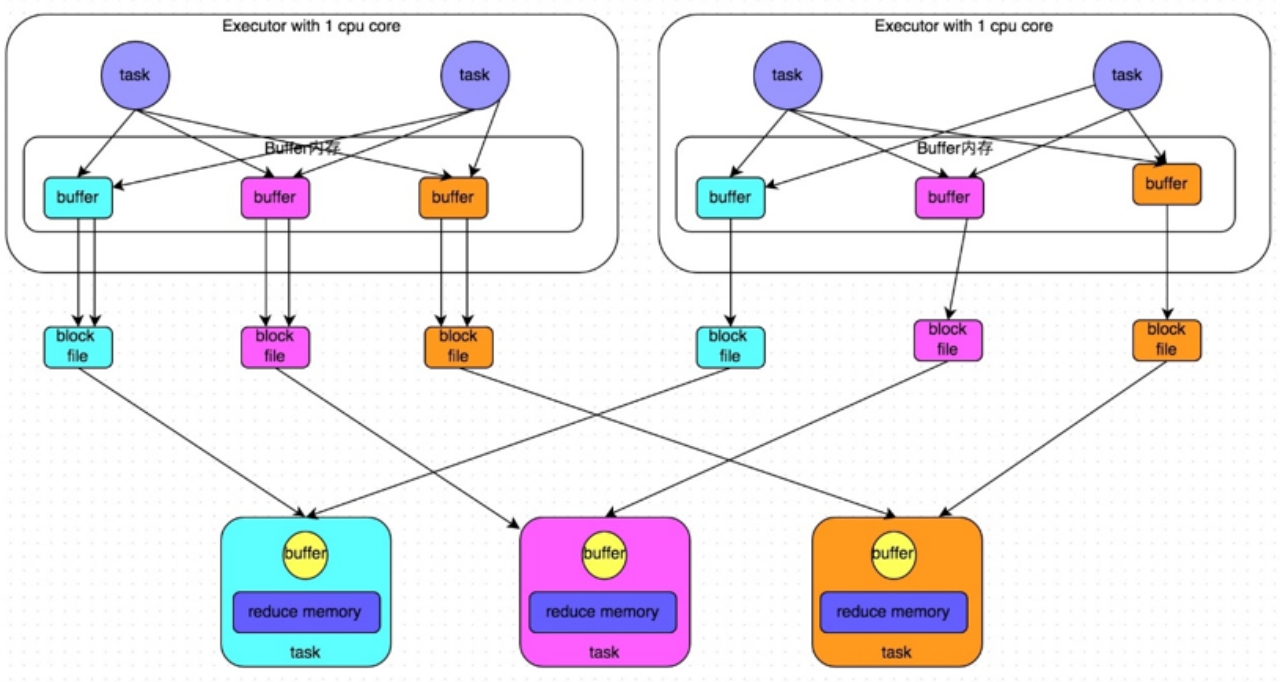
3.2.优化后的HashShuffle
缺点:提高性能优先,仍然还会有大量小文件
为了优化HashShuffleManager我们可以设置一个参数,spark.shuffle. consolidateFiles,该参数默认值为false,将其设置为true即可开启优化机制,通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了,此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件,也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
假设第二个stage有100个task,第一个stage有50个task,总共还是有10个Executor(Executor CPU个数为1),每个Executor执行5个task。那么原本使用未经优化的HashShuffleManager时,每个Executor会产生500个磁盘文件,所有Executor会产生5000个磁盘文件的。但是此时经过优化之后,每个Executor创建的磁盘文件的数量的计算公式为:CPU core的数量 * 下一个stage的task数量,也就是说,每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
4.SortShuffle解析
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass(默认,是忽略的排序的)机制。
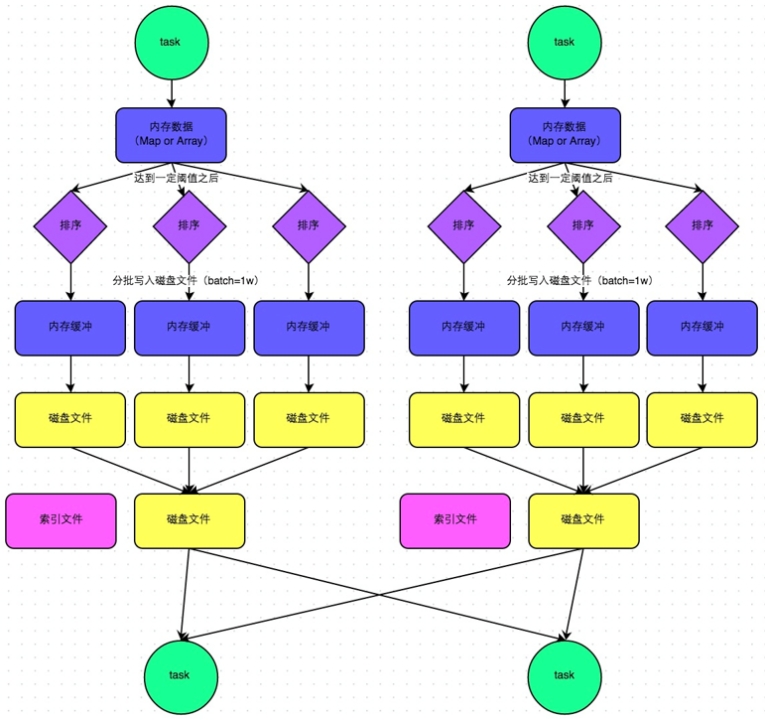
4.1.SortShuffle
优势:减少了小文件
在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。
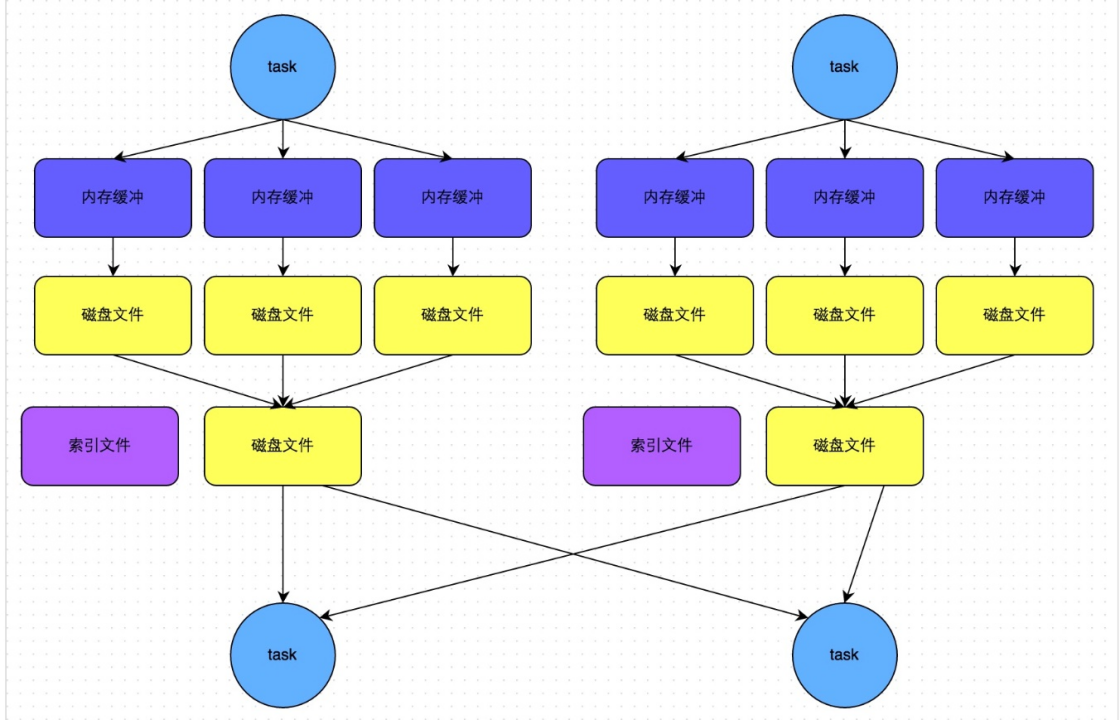
4.2.bypassShuffle
优势:减少了小文件,不排序,效率高。
bypassShuffle和SortShuffle的区别就是不对数据排序。
bypass运行机制的触发条件如下:
1)shuffle reduce task数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200。
2)不是聚合类的shuffle算子(比如reduceByKey不行)。
该模式下,每个task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
转载请注明:西门飞冰的博客 » Spark Shuffle解析