1.Phoenix定义
Phoenix 是HBASE的一个加分项,往往一些考虑使用HBASE的场景还是因为有着Phoenix的加持。如果只是单纯的考虑把数据存到HBASE,然后做一些简单的查询,Hbase一定是可以满足的。但是要对HBASE的数据做一些分析,这个时候HBASE 就出现问题了,因为HBASE本身没有分析的能力,HBASE只能做基于rowkey的简单查询,要通过HBASE做分析和统计是很难的。
我们要是既想通过HBASE存,又想通过HBASE分析,那么Phoenix就是一个必不可少的组件,它可以帮助HBASE扩展不少功能,带来很多新的特性,比如让HBASE具有分析能力,而且Phoenix使用起来也比较简单。
Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据。
优点:使用简单,直接能写sql,降低了HBASE的使用门槛。
缺点:因为多了一个中间层进行封装,所以效率没有自己设计rowKey时使用API高,性能较差。
官网地址:https://phoenix.apache.org/
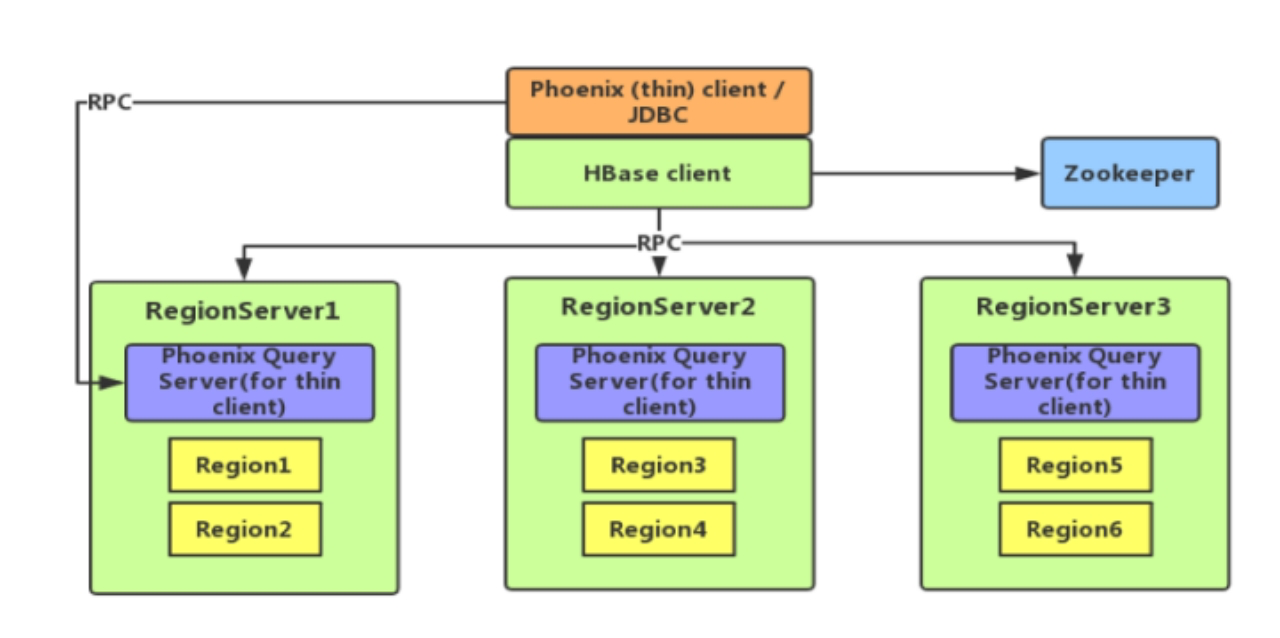
2.Phoenix架构
从Phoenix的架构图可以比较直观的体现出来,它就是一个客户端而已,底层还是HBASE。Phoenix客户端分为两种:
瘦客户端:将用户写好的sql转交给Phoenix Query服务,由Phoenix Query服务把sql解析成对应的HBASE操作,并交给HBASE执行,执行完成之后并负责把结果收集回来,并转换成二维表格返回给用户。Phoenix Query服务只针对瘦客户端。Phoenix Query服务需要放到Hbase的RegionServer里面。
胖客户端:不需要依赖Phoenix Query服务,客户端本身就可以完成sql的解析和提交操作(连接zookeeper)。
3.Phoenix安装
环境说明:
Hbase Version:2.0.5
Phoenix Version:5.0.0
(1)下载并解压安装包
wget http://mirror.bit.edu.cn/apache/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz tar xf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module/ cd /opt/module/ mv apache-phoenix-5.0.0-HBase-2.0-bin/ phoenix
(2)配置环境变量
#phoenix export PHOENIX_HOME=/opt/module/phoenix export PHOENIX_CLASSPATH=$PHOENIX_HOME export PATH=$PATH:$PHOENIX_HOME/bin
(3)复制相关jar包到hbase/lib下
cp phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase/lib/
(4)重启Hbase
(5)连接Phoenix
瘦客户端:
1、启动queryserver
/opt/module/phoenix/bin/queryserver.py start
2、执行客户端连接命令
/opt/module/phoenix/bin/sqlline-thin.py
胖客户端(需要连接Hbase的zookeeper):
/opt/module/phoenix/bin/sqlline.py hadoop01:2181
4.shell 操作Phoenix
如下命令是shell客户端可以进行的所有操作
0: jdbc:phoenix:thin:url=http://localhost:876> ! !quit !done !exit !connect !open !describe !indexes !primarykeys !exportedkeys !manual !importedkeys !procedures !tables !typeinfo !columns !reconnect !dropall !history !metadata !nativesql !dbinfo !rehash !verbose !run !batch !list !all !go !# !script !record !brief !close !closeall !isolation !outputformat !autocommit !commit !properties !rollback !help !? !set !save !scan !sql !call
1、创建schema 对应Hbase中的namespace
使用Phoenix创建schema需要额外在Hbase中添加一个配置(重启Hbase生效)
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
还需要在Phoenix添加对应的配置
vim /opt/module/phoenix/bin/hbase-site.xml
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
在phoenix中,创建schema和表等操作会自动转换为大写,若要小写,使用双引号,如”us_population”。
phoenix创建schema命令:
0: jdbc:phoenix:hadoop01:2181> create schema "mydb";
验证:phoenix创建schema后,hbase出现了同名的namespace说明创建成功
hbase(main):002:0> list_namespace NAMESPACE SYSTEM default hbase mydb
2、创建表:
在Phoenix创建表一定要有一个主键,这个主键是和hbase的rowkey做对应的。
create table "emp"( id varchar(20) primary key, // 主键对应hbase的rowkey name varchar(20), addr varchar(20) );
指定多个列的联合作为rowkey(列族)
create table "us_population" ( state char(2) not null, city varchar not null, population bigint constraint my_pk primary key (state, city));
3、插入数据(phoenix提供了upsert支持,相当于update+insert)
upsert into "emp" values('1001','zhangsan','beijing');
4、查询记录
0: jdbc:phoenix:hadoop01:2181> select * from "emp"; +-------+-----------+----------+ | ID | AME | ADDR | +-------+-----------+----------+ | 1001 | zhangsan | beijing | +-------+-----------+----------+ 1 row selected (0.087 seconds) 0: jdbc:phoenix:hadoop01:2181> select * from "emp" where id = '1001'; +-------+-----------+----------+ | ID | AME | ADDR | +-------+-----------+----------+ | 1001 | zhangsan | beijing | +-------+-----------+----------+
Hbase中查询对应数据
hbase(main):009:0> scan 'mydb:emp'' ROW COLUMN+CELL 1001 column=0:\x00\x00\x00\x00, timestamp=1672062328984, value=x 1001 column=0:\x80\x0B, timestamp=1672062328984, value=zhangsan 1001 column=0:\x80\x0C, timestamp=1672062328984, value=beijing
特别说明:
column后面的0是列族,因为列族是冗余存储的,所以要尽可能的简洁一些
\x00\x00\x00\x00 这些是列名,为了减少数据对磁盘空间的占用,Phoenix默认会对HBase中的列名做编码处理。具体规则可参考官网链接:https://phoenix.apache.org/columnencoding.html,若不想对列名编码,可在建表语句末尾加上COLUMN_ENCODED_BYTES = 0;
第一行数据的value=x,这个没有任何含义,主要是为了保证rowkey的存在
5、删除记录
delete from "emp" where id = '1001';
Hbase 中验证对应的数据删除
hbase(main):010:0> scan 'mydb:emp',{RAW=>true,VERSIONS=>3}
ROW COLUMN+CELL
1001 column=0:, timestamp=1672061971367, type=DeleteFamily
1001 column=0:\x00\x00\x00\x00, timestamp=1672061865458, value=x
1001 column=0:\x80\x0B, timestamp=1672061865458, value=zhangsan
1001 column=0:\x80\x0C, timestamp=1672061865458, value=beijing
5.数字编码问题
create table emp2(
id varchar(20) primary key,
name varchar(20),
addr varchar(20),
salary bigint
)
COLUMN_ENCODED_BYTES = 0;
upsert into emp2 (id, name, addr, salary) values('1001','zhangsan','beijing',123456);
数据在phoenix显示是正常的
0: jdbc:phoenix:hadoop01:2181> select * from emp2; +-------+-----------+----------+---------+ | ID | NAME | ADDR | SALARY | +-------+-----------+----------+---------+ | 1001 | zhangsan | beijing | 123456 | +-------+-----------+----------+---------+



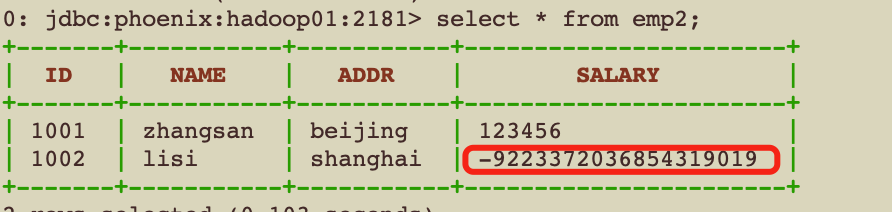
那么现在问题来了,通过phoenix和Hbase写入的数据两边识别结果互相错误,怎么回事?怎么解决?
这个问题就涉及到了0和1谁大的问题,在数学中,1一定大于0,但是在二进制中0一定大于1,因为二进制中0是正数,1是负数。就是因为在0和1谁大的问题上,phoenix和hbase各自认为的观点不同,所以才导致了这个问题。
6.JDBC操作
注意:瘦/胖客户端需要分开写,因为有依赖冲突,同时只能用一个。
6.1.瘦客户端
(1) 导入Maven依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.1-b06</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
(2)编写代码
public class PhoenixThinClient {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
testSelect();
}
public static void testSelect() throws ClassNotFoundException, SQLException {
// 注册驱动
Class.forName("org.apache.phoenix.queryserver.client.Driver");
// 获取连接
String url = "jdbc:phoenix:thin:url=http://hadoop01:8765;serialization=PROTOBUF";
Connection connection = DriverManager.getConnection(url);
// 编写sql
String sql = "select id , name , addr from mydb.emp where id = ?" ;
// 预编译sql
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// 设置参数
preparedStatement.setString(1,"1001");
// 执行SQL
ResultSet resultSet = preparedStatement.executeQuery();
// 处理结果
if (resultSet.next()){
String id = resultSet.getString("id");
String name = resultSet.getString("name");
String addr = resultSet.getString("addr");
System.out.println(id + ":" + name + ":" + addr);
}
// 关闭连接
resultSet.close();
preparedStatement.close();
connection.close();
}
}
6.2.胖客户端
(1)导入Maven依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.1-b06</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
(2)编写代码
public class PhoenixThickClient {
public static void main(String[] args) throws Exception {
testSelect();
}
//查询数据
public static void testSelect() throws Exception {
// 注册驱动
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
// 获取连接
String url = "jdbc:phoenix:hadoop01:2181" ;
Properties properties = new Properties();
properties.put("phoenix.schema.isNamespaceMappingEnabled" , "true") ;
Connection connection = DriverManager.getConnection(url ,properties);
// 编写sql
String sql = "select id , name , addr from mydb.emp where id = ?" ;
// 预编译参数
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// 设置参数
preparedStatement.setString(1, "1001");
// 执行sql
ResultSet resultSet = preparedStatement.executeQuery();
// 处理结果
if(resultSet.next()){
String id = resultSet.getString("id");
String name = resultSet.getString("name");
String addr = resultSet.getString("addr");
System.out.println(id + " : " + name + " : " + addr) ;
}
// 关闭连接
resultSet.close();
preparedStatement.close();
connection.close();
}
}
转载请注明:西门飞冰的博客 » Hbase整合Phoenix之介绍部署和使用



