1.FlinkAPI的join方式
使用Flink API要做双流join的话,flink提供了两种方式,一种是基于窗口的window join和基于状态的lnterval join
Flink Join算子有非常严厉的限制,就是必须基于时间
通过API实现双流join有个弊端,就是不管是基于窗口join还是状态join都只支持内连接
内连接就是只能把两条流完全匹配的数据查询出来,如果想把其中一条流数据完全展示出来,不管另外一条流有没有匹配数据都要展现出来的话,直接调用它现有的API做不到,除非通过collect把两个流连接在一起后底层怎么写自己进行实现,但是这样就比较麻烦。
这个时候要支持其他连接就需要用到flink sql 进行join了
2.基于窗口Window join
Flink为基于一段时间的双流合并专门提供了一个窗口联结(window join)算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。
代码示例:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
public class WindowJoinTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 需要定义两条流,有相同的key
SingleOutputStreamOperator<Event> stream1 = env.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./cart", 3000L),
new Event("Alice", "./fav", 8000L),
new Event("Bob", "./home", 15000L),
new Event("Cary", "./prod?id=1", 16000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(0))
.withTimestampAssigner((element, recordTimestamp) -> element.timestamp )
);
SingleOutputStreamOperator<Tuple3<String, Integer, Long>> stream2 = env.fromElements(
Tuple3.of("Alice", 35, 2000L),
Tuple3.of("Bob", 20, 8000L),
Tuple3.of("Alice", 17, 9000L),
Tuple3.of("Bob", 20, 12000L),
Tuple3.of("Mary", 50, 17000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(0))
.withTimestampAssigner((element, recordTimestamp) -> element.f2 )
);
// 调用DataStream的.join()方法来合并两条流,得到一个JoinedStreams
stream1.join(stream2)
// 通过where和equalTo方法指定两条流中联结的key
.where(value -> value.user) // 用来指定第一条流中的key
.equalTo(value -> value.f0) // 指定了第二条流中的key
// 通过windos开窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 调用apply传入联结窗口函数进行处理计算
.apply(new JoinFunction<Event, Tuple3<String, Integer, Long>, String>() {
@Override
public String join(Event first, Tuple3<String, Integer, Long> second) throws Exception {
return first + " --> " + second;
}
})
.print();
env.execute();
}
}
输出结果:
Event{user='Alice', url='./home', timestamp=1970-01-01 08:00:01.0} --> (Alice,35,2000)
Event{user='Alice', url='./home', timestamp=1970-01-01 08:00:01.0} --> (Alice,17,9000)
Event{user='Alice', url='./cart', timestamp=1970-01-01 08:00:03.0} --> (Alice,35,2000)
Event{user='Alice', url='./cart', timestamp=1970-01-01 08:00:03.0} --> (Alice,17,9000)
Event{user='Alice', url='./fav', timestamp=1970-01-01 08:00:08.0} --> (Alice,35,2000)
Event{user='Alice', url='./fav', timestamp=1970-01-01 08:00:08.0} --> (Alice,17,9000)
Event{user='Bob', url='./cart', timestamp=1970-01-01 08:00:02.0} --> (Bob,20,8000)
Event{user='Bob', url='./home', timestamp=1970-01-01 08:00:15.0} --> (Bob,20,12000)
3.基于窗口join缺点
滚动窗口
缺点:容易丢数据,本应该关联的两个元素没有在一个窗口就会导致关联不上
滑动窗口
缺点:对窗口中的元素进行关联处理,会出现数据重叠的问题,导致数据的重复处理
基于窗口的双流join 要么会出现关联不上,要么会出现重复处理的情况,要解决的话都可以通过状态来进行解决,这个时候lnterval join就该上场了,它是基于状态的。
4.基于状态lnterval join
间隔联结(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
间隔连接的原理:
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作A)中的任意一个数据元素a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以a的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫B)中的数据元素b,如果它的时间戳落在了这个区间范围内,a和b就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
这里需要注意,做间隔联结的两条流A和B,也必须基于相同的key;下界lowerBound应该小于等于上界upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
如下图所示:我们可以清楚地看到间隔联结的方式
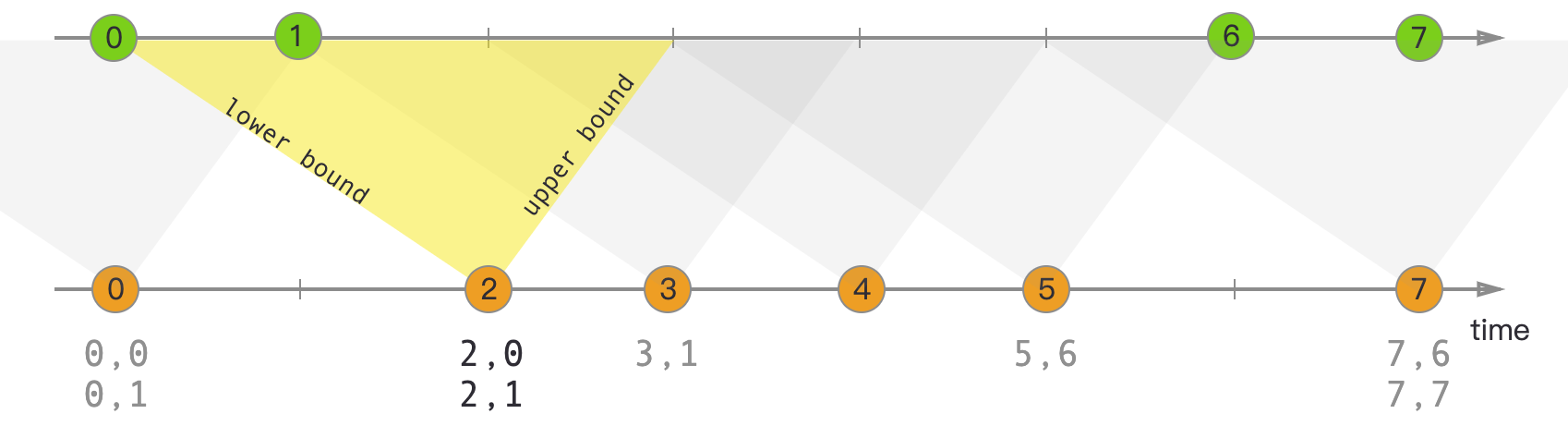
间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,interval join做匹配的时间段是基于流中数据的,所以并不确定;而且流B中的数据可以不只在一个区间内被匹配。
示例代码:
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream
//两条流进行连接之前需要先keyBy,目的是指明两条流的连接条件,没有连接条件就会造成笛卡尔积
.keyBy(<KeySelector>)
// intervalJoin 指定连接的两条流
.intervalJoin(greenStream.keyBy(<KeySelector>))
// between 指定关联时间的上界和下界
.between(Time.milliseconds(-2), Time.milliseconds(1))
// process 指定两条流连接后对数据进行的处理操作
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
5.intervalJoin基本用法
定义员工POJO类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Emp {
private Integer empno;
private String ename;
private Integer deptno;
private Long ts;
}
定义部门POJO类:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Dept {
private Integer deptno;
private String dname;
private Long ts;
}
示例代码:
public class IntervalJoin {
public static void main(String[] args) throws Exception {
// 指定流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(2);
// 从指定端口读取员工数据 并指定Watermark
SingleOutputStreamOperator<Emp> empDS = env.socketTextStream("127.0.0.1", 8888)
.map(new MapFunction<String, Emp>() {
@Override
public Emp map(String lineStr) throws Exception {
String[] fieldArr = lineStr.split(",");
return new Emp(
Integer.valueOf(fieldArr[0]),
fieldArr[1],
Integer.valueOf(fieldArr[2]),
Long.valueOf(fieldArr[3])
);
}
}).assignTimestampsAndWatermarks(
WatermarkStrategy.
<Emp>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Emp>() {
@Override
public long extractTimestamp(Emp emp, long l) {
return emp.getTs();
}
}
)
);
empDS.print("emp:");
// 从指定端口读取部门数据 并指定Watermark
SingleOutputStreamOperator<Dept> deptDS = env.socketTextStream("127.0.0.1", 8889)
.map(new MapFunction<String, Dept>() {
@Override
public Dept map(String jsonStr) throws Exception {
String[] fieldArr = jsonStr.split(",");
return new Dept(Integer.valueOf(fieldArr[0]), fieldArr[1], Long.valueOf(fieldArr[2]));
}
}
).assignTimestampsAndWatermarks(
WatermarkStrategy
.<Dept>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Dept>() {
@Override
public long extractTimestamp(Dept dept, long l) {
return dept.getTs();
}
}
)
);
deptDS.print("dept");
// 使用intervalJoin进行连接
SingleOutputStreamOperator<Tuple2<Emp, Dept>> processDS = empDS
.keyBy(Emp::getDeptno)
.intervalJoin(deptDS.keyBy(Dept::getDeptno))
.between(Time.milliseconds(-5), Time.milliseconds(5))
.process(
new ProcessJoinFunction<Emp, Dept, Tuple2<Emp, Dept>>() {
@Override
public void processElement(Emp emp, Dept dept, Context ctx, Collector<Tuple2<Emp, Dept>> out) throws Exception {
out.collect(Tuple2.of(emp, dept));
}
}
);
processDS.print(">>>");
env.execute();
}
}

输出结果:
6.
1、通过connect把两条流连接在一起,然后底层维护两个状态,分别存放左流和右流数据
(1)判断数据是否迟到,如果迟到则不进行处理
(2)将当前数据放到状态中缓存
(3)将当前数据和另一条流中以及缓存的数据进行关联
(4)清除状态
具体源码分析过程如下:
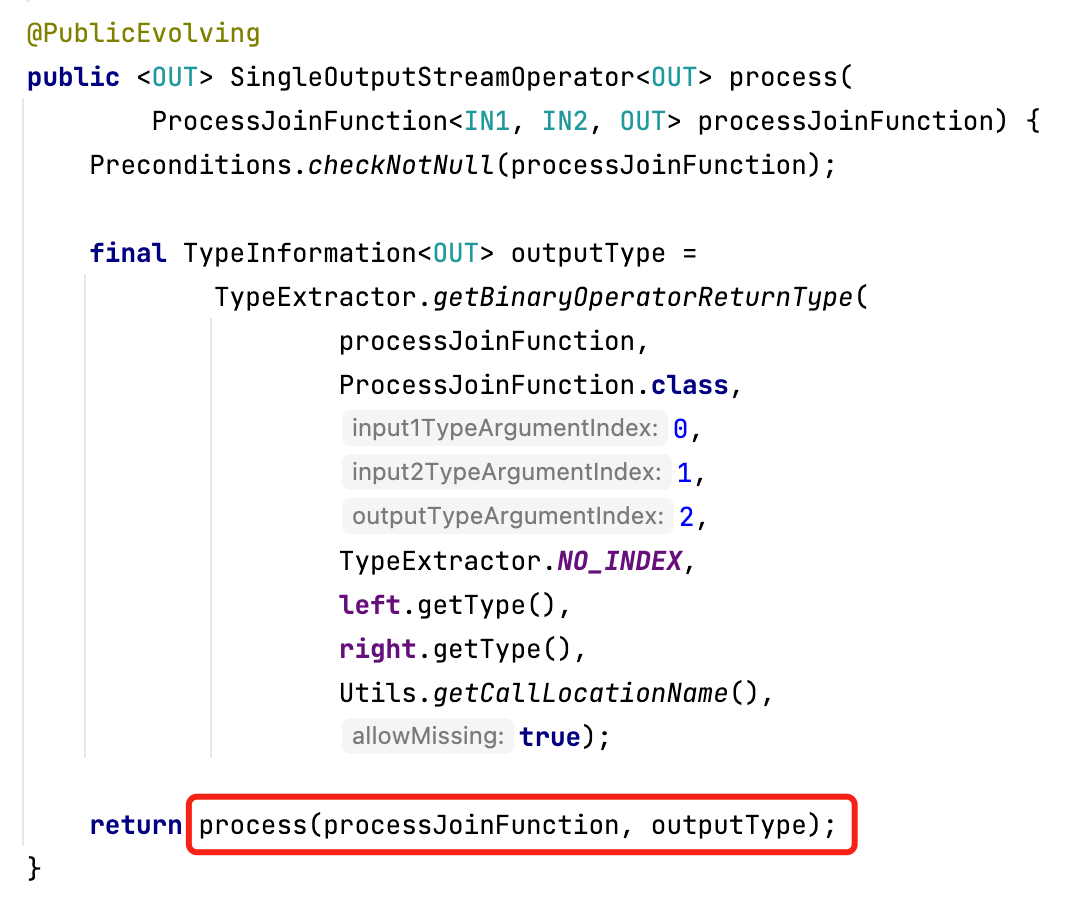

3、connect只是把两条流放到一起,在处理的时候,还是要对两条流进行单独处理
数据来了之后先把数据存储到状态中,Map State的key value形式,key就是流中的这条元素对应的事件时间,Long类型的时间,value就是这个时间它所对应的所有元素,List集合形式,因为同样的时间可能有多条数据。



5、进入processElement方法,看看具体是如何处理数据的。
(1)判断数据是否迟到,如果迟到则不进行处理
(2)将当前数据放到状态中缓存
(3)将当前数据和另一条流中以及缓存的数据进行关联
(4)清除状态
private <THIS, OTHER> void processElement(
final StreamRecord<THIS> record,
final MapState<Long, List<IntervalJoinOperator.BufferEntry<THIS>>> ourBuffer,
final MapState<Long, List<IntervalJoinOperator.BufferEntry<OTHER>>> otherBuffer,
final long relativeLowerBound,
final long relativeUpperBound,
final boolean isLeft)
throws Exception {
final THIS ourValue = record.getValue(); // 拿到数据
final long ourTimestamp = record.getTimestamp(); //拿到数据的事件时间
if (ourTimestamp == Long.MIN_VALUE) { // 事件时间要是等于最小值,说明没有指定事件时间,抛出异常
throw new FlinkException(
"Long.MIN_VALUE timestamp: Elements used in "
+ "interval stream joins need to have timestamps meaningful timestamps.");
}
if (isLate(ourTimestamp)) { // 判断数据是否迟到,如果迟到直接结束方法
return;
}
addToBuffer(ourBuffer, ourValue, ourTimestamp); // 数据到来后,先放入状态里面缓存起来
// 将当前数据和另外一条流中缓存的数据进行关联
for (Map.Entry<Long, List<BufferEntry<OTHER>>> bucket : otherBuffer.entries()) {
// 获取状态中存储的时间
final long timestamp = bucket.getKey();
// 如果当前流中的时间,比另外一条流缓存的最小时间还要小,或者比最大时间还要大,说明数据不在关联范围,则跳过这条数据
if (timestamp < ourTimestamp + relativeLowerBound || timestamp > ourTimestamp + relativeUpperBound) {
continue;
}
// 数据在时间范围之内,通过collect进行关联
for (BufferEntry<OTHER> entry : bucket.getValue()) {
if (isLeft) {
collect((T1) ourValue, (T2) entry.element, ourTimestamp, timestamp);
} else {
collect((T1) entry.element, (T2) ourValue, timestamp, ourTimestamp);
}
}
}
// 清理状态的方法,时间到了最大时间+时间的上界,注册一个定时器
long cleanupTime =
(relativeUpperBound > 0L) ? ourTimestamp + relativeUpperBound : ourTimestamp;
if (isLeft) {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_LEFT, cleanupTime);
} else {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_RIGHT, cleanupTime);
}
}
isLate 判断数据是否迟到方法:
private boolean isLate(long timestamp) {
long currentWatermark = internalTimerService.currentWatermark();
return currentWatermark != Long.MIN_VALUE && timestamp < currentWatermark;
}
addToBuffer把数据添加到状态源码:
private static <T> void addToBuffer(
final MapState<Long, List<IntervalJoinOperator.BufferEntry<T>>> buffer,
final T value,
final long timestamp)
throws Exception {
List<BufferEntry<T>> elemsInBucket = buffer.get(timestamp);
if (elemsInBucket == null) {
elemsInBucket = new ArrayList<>();
}
elemsInBucket.add(new BufferEntry<>(value, false));
buffer.put(timestamp, elemsInBucket);
}
collect 连接方法:
private void collect(T1 left, T2 right, long leftTimestamp, long rightTimestamp)
throws Exception {
final long resultTimestamp = Math.max(leftTimestamp, rightTimestamp);
collector.setAbsoluteTimestamp(resultTimestamp);
context.updateTimestamps(leftTimestamp, rightTimestamp, resultTimestamp);
userFunction.processElement(left, right, context, collector);
}
清除状态方法的定时器:
@Override
public void onEventTime(InternalTimer<K, String> timer) throws Exception {
long timerTimestamp = timer.getTimestamp();
String namespace = timer.getNamespace();
logger.trace("onEventTime @ {}", timerTimestamp);
switch (namespace) {
case CLEANUP_NAMESPACE_LEFT:
{
long timestamp =
(upperBound <= 0L) ? timerTimestamp : timerTimestamp - upperBound;
logger.trace("Removing from left buffer @ {}", timestamp);
leftBuffer.remove(timestamp);
break;
}
case CLEANUP_NAMESPACE_RIGHT:
{
long timestamp =
(lowerBound <= 0L) ? timerTimestamp + lowerBound : timerTimestamp;
logger.trace("Removing from right buffer @ {}", timestamp);
rightBuffer.remove(timestamp);
break;
}
default:
throw new RuntimeException("Invalid namespace " + namespace);
}
}
7.intervalJoin的WM生成
单并行度:

输出结果:
emp:> Emp(empno=100, ename=zhangsan, depeno=10, ts=9) dept> Dept(deptno=10, dname=baigong, ts=9) >>>> (Emp(empno=100, ename=zhangsan, depeno=10, ts=9),Dept(deptno=10, dname=baigong, ts=9)) emp:> Emp(empno=100, ename=zhangsan, depeno=10, ts=8) >>>> (Emp(empno=100, ename=zhangsan, depeno=10, ts=8),Dept(deptno=10, dname=baigong, ts=9)) emp:> Emp(empno=100, ename=zhangsan, depeno=10, ts=7) // 时间戳为7的数据没有join上,因为它属于迟到数据
问题原因:
1、根据水位线生成规则,水位线生成时间是事件时间减去1毫秒,所以时间为9到达的数据水位线是8,根据水位线递增原则,水位线事件取事件最大时间,后面数据时间都比9小,所以水位线时间不变
2、根据水位线传递规则,两条流合并 取水位线最小时间,所以合流之后的水位线也是8
3、时间为7的数据,属于迟到数据(事件时间小于水位线时间,不进行处理),所以没有join上
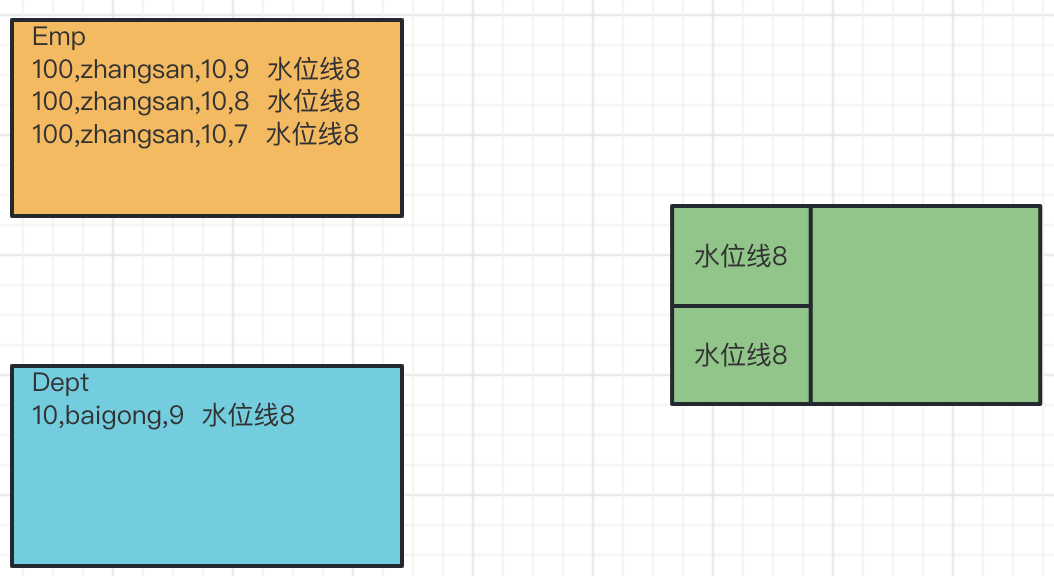
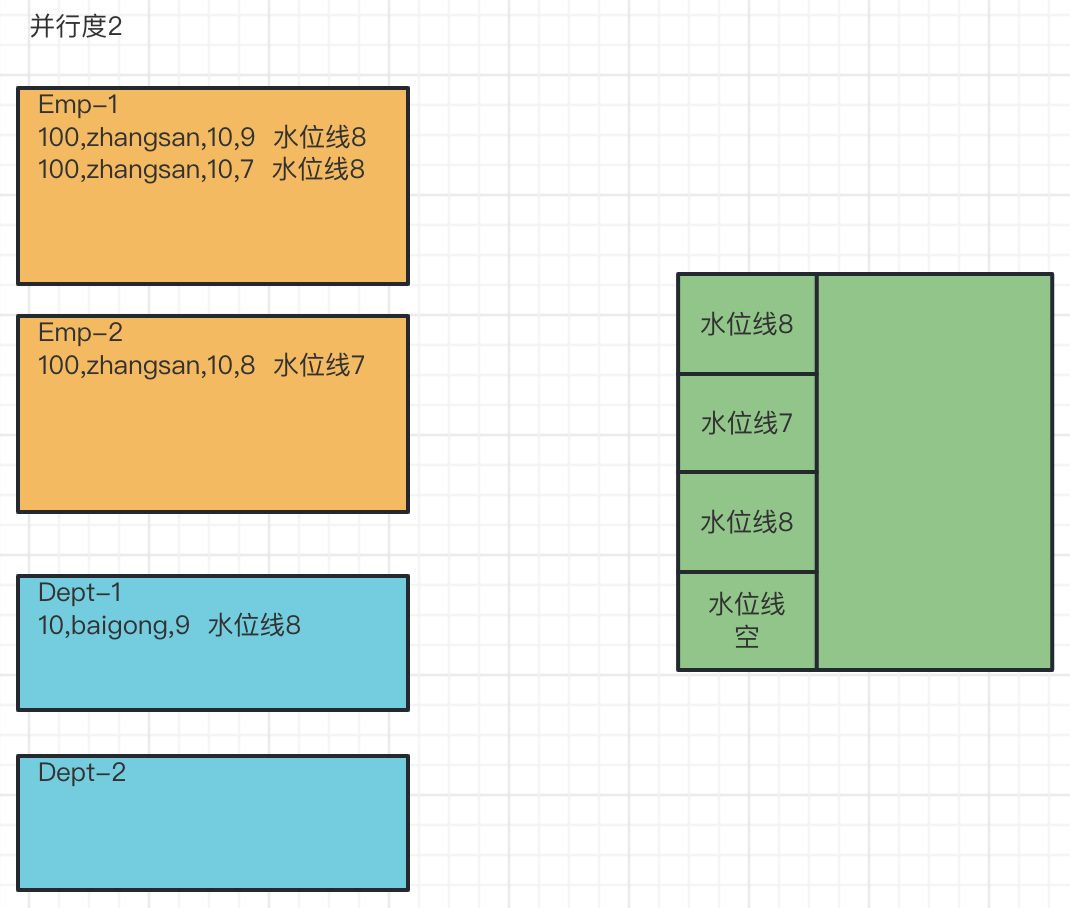
多并行度:

原因分析:
1、因为有两个并行度,当员工和部门的第一条数据来的时候都是交给第一个并行度来进行处理,当员工第二条数据进来后,就交给并行度2进行处理,这时候两个并行度的水位线是不一样的,并行度1水位线是8,并行度2水位线是7
2、根据水位线传递原则,两条流4个并行度合并,水位线取最小时间,也就是7,所以合流之后的水位线是7
3、所以这个时候时间为7的数据进来,不算迟到数据,可以join上
转载请注明:西门飞冰的博客 » Flink 基于API的双流join