springboot Actuator指标监控(基于k8s 和prometheus 实现)

11个月前 (06-14) 2286℃ 4喜欢
11个月前 (06-14) 2286℃ 4喜欢
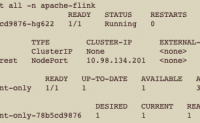
11个月前 (06-06) 1529℃ 1喜欢

11个月前 (06-05) 1247℃ 2喜欢

11个月前 (06-05) 1208℃ 0喜欢
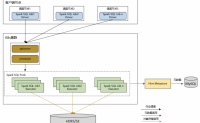
11个月前 (06-05) 2℃ 0喜欢
11个月前 (06-05) 1252℃ 1喜欢
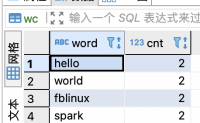
11个月前 (06-05) 890℃ 0喜欢
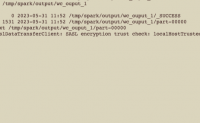
11个月前 (06-05) 1130℃ 0喜欢

11个月前 (06-05) 1023℃ 0喜欢
11个月前 (06-05) 1534℃ 2喜欢