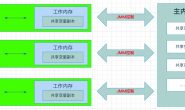
1.介绍
基于SQL的过滤,因为对SQL语句执行了校验和SQL语法的解析,执行效率相对于tag方式较低,同时作为自定义属性,他不像tag是标准的结构体,所以在进行消息筛选的时候,相比起tag过滤,这种SQL过滤的方式,执行效率是相对比较慢的,只适用于数据量不大,需要灵活来进行调整的时候,才会考虑用它。
1.1.服务端配置
RocketMQ 默认并未开启自定义属性SQL过滤的选项,需要在配置文件中额外开启,如下所示:
enablePropertyFilter=true
2.消息生产者
消息发送方和标准发送有两点变化:
- 可以不设置消息的Tag和Key,转而使用用户自定义属性,这里实现了source与id两个自定义属性的赋值
- 利用message.putUserProperty为用户属性赋值
//消息过滤案例生产者
@Slf4j
public class SfProducer {
public static void main(String[] args) {
//DefaultMQProducer用于发送非事务消息
DefaultMQProducer producer = new DefaultMQProducer("sf-producer-group");
//注册NameServer地址
producer.setNamesrvAddr("172.16.247.3:9876");
try {
//启动生产者实例
producer.start();
for (Integer i = 0; i < 10; i++) {
Thread.sleep(1000);
Integer rnd = new Random().nextInt(10);
//用户自定义属性
String source = "";
switch (rnd % 3) {
case 0:
source = "jd";
break;
case 1:
source = "tmall";
break;
case 2:
source = "taobao";
break;
}
//消息数据
String data = "第" + i + "条消息数据";
//消息主题,使用用户自定义属性时可以不设置tag与key
Message message = new Message("sf-sample-data", data.getBytes());
message.putUserProperty("id", i.toString());
message.putUserProperty("source", source);
//发送结果
SendResult result = producer.send(message);
log.info("id:{},source:{},data:{}", i.toString(), source, data);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//关闭连接
producer.shutdown();
log.info("连接已关闭");
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
运行结果:
id:0,source:jd,data:第0条消息数据 id:1,source:tmall,data:第1条消息数据 id:2,source:taobao,data:第2条消息数据 id:3,source:taobao,data:第3条消息数据 id:4,source:jd,data:第4条消息数据 id:5,source:tmall,data:第5条消息数据 id:6,source:jd,data:第6条消息数据 id:7,source:tmall,data:第7条消息数据 id:8,source:jd,data:第8条消息数据 id:9,source:taobao,data:第9条消息数据
3.消息消费者
京东消费者
京东消费者负责消费source=’jd’的数据,和标准消费者最大的不同便是在subscribe方法第二个参数不再是Tag,而改为MessageSelector.bySql方法,利用WHERE子句写法对自定义属性实现过滤,源码如下:
@Slf4j
public class SfJDConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("sf-jd-consumer-group");
consumer.setNamesrvAddr("172.16.247.3:9876");
consumer.setMessageModel(MessageModel.CLUSTERING);
//利用SQL WHERE子句写法对自定义属性进行过滤
consumer.subscribe("sf-sample-data", MessageSelector.bySql("source='jd'"));
// 注册消息监听者
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
list.forEach(msg -> {
log.info("id:{},source:{},data:{}", msg.getUserProperty("id"), msg.getUserProperty("source"), new String(msg.getBody()));
});
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
log.info("集群消费者启动成功,正在监听新消息");
}
}
运行结果:
集群消费者启动成功,正在监听新消息 id:8,source:jd,data:第8条消息数据 id:4,source:jd,data:第4条消息数据 id:0,source:jd,data:第0条消息数据 id:6,source:jd,data:第6条消息数据
阿里消费者
阿里消费者负责消费天猫与淘宝的数据,与京东消费者最明显的区别是:
因为业务范围不同,消费者组不一样;
bySQL的要获取多个数值,可用下面语法
- source in (‘tmall’,’taobao’)
- source = ‘tmall’ or source = ‘taobao’
//利用SQL WHERE子句写法对自定义属性进行过滤
consumer.subscribe("sf-sample-data", MessageSelector.bySql("source in ('tmall' ,'taobao')"));
运行结果:
集群消费者启动成功,正在监听新消息 id:9,source:taobao,data:第9条消息数据 id:5,source:tmall,data:第5条消息数据 id:7,source:tmall,data:第7条消息数据 id:3,source:taobao,data:第3条消息数据 id:2,source:taobao,data:第2条消息数据 id:1,source:tmall,data:第1条消息数据
转载请注明:西门飞冰的博客 » RocketMQ消费者基于自定义属性实现SQL过滤