1.简介
在实际工作中,绝大多数的离线数仓,批处理作业,都是使用SQL脚本开发的,通过SQL语句实现处理的逻辑。得益于spark的优良性能,尤其是在spark 3.0之后,spark sql的性能有了大幅度的提升。目前在绝大多数的公司的数仓团队中,都是通过spark sql来开发批处理作业的。所以在大数据存算分离的大背景下,spark sql 容器化也是必要的。
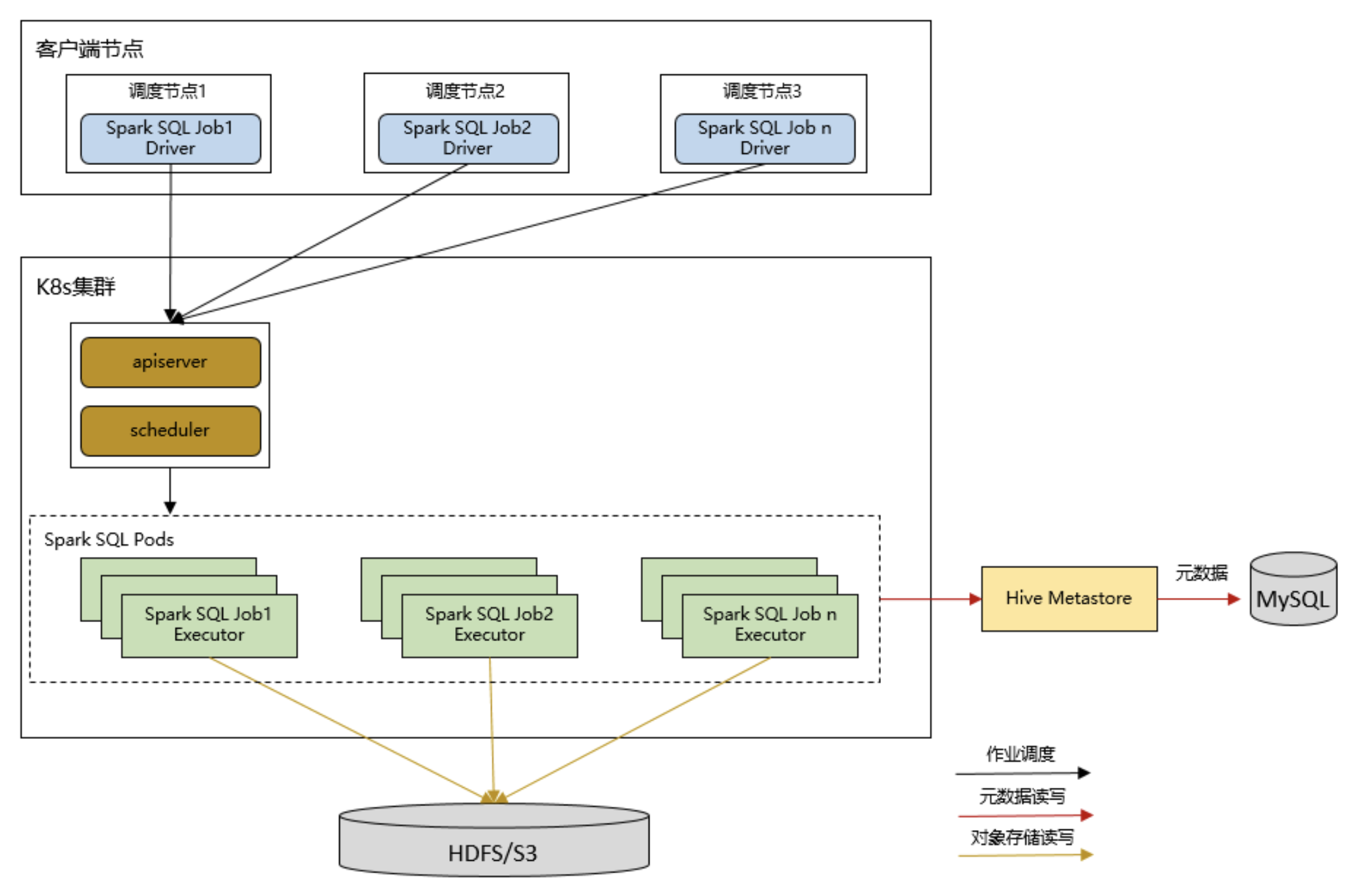
2.Spark Sql on k8s架构图
如下图所示,spark sql是以client模式运行的,也就是driver运行在k8s之外,Executor运行在k8s之内。spark sql要对数据库和数据表进行操作,就需要通过hive metastore获取hive的元数据信息。
在存算分离架构中,spark的计算是在k8s里面完成的,而数据则存储在外部的HDFS 或者 对象存储中。
3.环境准备
1、提前安装好Hadoop(3.1.3)、hive(3.1.2)、spark(3.2.3)环境,hive启动Metastore服务。
2、配置好spark on hive的运行环境。
4.特别说明
1、使用spark-submit提交任务到k8s是在k8s服务器上执行的操作,需要拷贝一份hive的整个二进制目录和相关依赖到spark- submit提交任务的节点,负责使用spark- submit提交任务到k8s集群会报相关hive的依赖找不到。
2、因为k8s和hadoop 是两个独立的集群,服务器操作k8s集群用的是root账号,操作Hadoop 集群用的是Hadoop账号。而使用spark提交任务到k8s是在k8s服务器上执行操作,所以使用的是root用户,需要Hadoop给相关目录配置root的可操作权限。
hdfs dfs -chown -R hadoop:root /user/ hdfs dfs -chmod -R 775 /user
5.
由于Spark SQL以client模式运行,Driver运行在K8s外面,Executor运行在K8s里面,倘若我们要使用Spark History Server, 它但要求driver和executor的eventLog需要指向同一个存储路径,此场景下使用PV不方便,因为PV 的实际路径与Pod容器里挂载路径通常是不一样的,为此,在Spark SQL On K8s 与Hadoop集成的场景中,推荐将eventLog保存到HDFS。
1、在HDFS上创建目录保存eventLog
hadoop fs -mkdir /spark hadoop fs -mkdir /spark/eventLog
2、创建ConfigMap,保存Hadoop配置文件信息
[root@k8s-demo001 ~]# cat spark-conf-hadoop.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: spark-conf-hadoop
namespace: apache-spark
annotations:
kubesphere.io/creator: admin
data:
core-site.xml: |
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-test01:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.users</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml: |
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-test01:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-test02:9868</value>
</property>
</configuration>
3、部署historyserver,采用Deployment + Service + Ingress方式
[root@k8s-demo001 ~]# cat spark-historyserver-hadoop.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: apache-spark
labels:
app: spark-historyserver
name: spark-historyserver
name: spark-historyserver
spec:
replicas: 1
selector:
matchLabels:
name: spark-historyserver
template:
metadata:
namespace: apache-spark
labels:
app: spark-historyserver
name: spark-historyserver
spec:
hostAliases: # hosts配置
- ip: "172.16.252.105"
hostnames:
- "k8s-demo001"
- ip: "172.16.252.134"
hostnames:
- "k8s-demo002"
- ip: "172.16.252.135"
hostnames:
- "k8s-demo003"
- ip: "172.16.252.136"
hostnames:
- "k8s-demo004"
containers:
- name: spark-historyserver
image: apache/spark:v3.2.3
imagePullPolicy: IfNotPresent
args: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.history.HistoryServer"]
env:
- name: TZ
value: Asia/Shanghai
- name: HADOOP_USER_NAME
value: hadoop
- name: SPARK_USER
value: hadoop
# 如果不使用configmap,则通过SPARK_HISTORY_OPTS配置
- name: SPARK_HISTORY_OPTS
value: "-Dspark.eventLog.enabled=true -Dspark.eventLog.dir=hdfs://hadoop-test01:8020/spark/eventLog -Dspark.history.fs.logDirectory=hdfs://hadoop-test01:8020/spark/eventLog"
ports:
- containerPort: 18080
volumeMounts:
- name: spark-conf
mountPath: /opt/spark/conf/core-site.xml
subPath: core-site.xml
- name: spark-conf
mountPath: /opt/spark/conf/hdfs-site.xml
subPath: hdfs-site.xml
volumes: # 挂载卷配置
- name: spark-conf
configMap:
name: spark-conf-hadoop
#---
#kind: Service
#apiVersion: v1
#metadata:
# namespace: apache-spark
# name: spark-historyserver
#spec:
# type: NodePort
# ports:
# - port: 18080
# nodePort: 31082
# selector:
# name: spark-historyserver
# ingress按实际情况配置
---
apiVersion: v1
kind: Service
metadata:
labels:
app: spark-historyserver
name: spark-historyserver
name: spark-historyserver
namespace: apache-spark
spec:
selector:
app: spark-historyserver
ports:
- port: 18080
protocol: TCP
targetPort: 18080
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: apache-spark
name: spark-historyserver
annotations:
nginx.ingress.kubernetes.io/default-backend: ingress-nginx-controller
nginx.ingress.kubernetes.io/use-regex: 'true'
spec:
ingressClassName: nginx
rules:
- host: "spark.k8s.io"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: spark-historyserver
port:
number: 18080
6.spark sql on k8s 测试
[root@k8s-demo001 ~]# cat /data/nginx_down/executor-sql-hadoop.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app.kubernetes.io/name: apache-spark
app.kubernetes.io/instance: apache-spark
app.kubernetes.io/version: v3.2.3
namespace: apache-spark
name: executor
spec:
serviceAccountName: spark-service-account
hostAliases:
- ip: "172.16.252.105"
hostnames:
- "k8s-demo001"
- ip: "172.16.252.134"
hostnames:
- "k8s-demo002"
- ip: "172.16.252.135"
hostnames:
- "k8s-demo003"
- ip: "172.16.252.136"
hostnames:
- "k8s-demo004"
containers:
- image: apache/spark:v3.2.3
name: executor
imagePullPolicy: IfNotPresent
env:
- name: TZ
value: Asia/Shanghai
- name: HADOOP_USER_NAME
value: hadoop
- name: SPARK_USER
value: hadoop
resources:
requests:
cpu: 1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: spark-logs # 挂载日志
mountPath: /opt/spark/logs
volumes:
- name: spark-logs
persistentVolumeClaim:
claimName: spark-logs-pvc
2、在driver运行节点(spark-submit提交节点)创建日志保存路径。
/opt/spark/logs
3、使用-e执行SQL语句
./spark-3.2.3-hadoop/bin/spark-submit \ --name spark-sql-test \ --verbose \ --master k8s://https://172.16.252.105:6443 \ --deploy-mode client \ --conf spark.network.timeout=300 \ --conf spark.executor.instances=3 \ --conf spark.driver.cores=1 \ --conf spark.executor.cores=1 \ --conf spark.driver.memory=1024m \ --conf spark.executor.memory=1024m \ --conf spark.driver.host=k8s-demo001 \ --conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/driver-sql-hadoop-1.log" \ --conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/executor-sql-hadoop-1.log" \ --conf spark.eventLog.enabled=true \ --conf spark.eventLog.dir=hdfs://hadoop-test01:8020/spark/eventLog \ --conf spark.history.fs.logDirectory=hdfs://hadoop-test01:8020/spark/eventLog \ --conf spark.kubernetes.namespace=apache-spark \ --conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \ --conf spark.kubernetes.container.image=apache/spark:v3.2.3 \ --conf spark.kubernetes.executor.podTemplateFile=http://172.16.252.105:8080/executor-sql-hadoop.yaml \ --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver \ -e \ " DROP TABLE IF EXISTS spark_dept; CREATE TABLE spark_dept(deptno int, dname string, loc string); INSERT INTO spark_dept VALUES (10, 'ACCOUNTING', 'NEW YORK'); select * from spark_dept; select count(*) from spark_dept where deptno=10 "
说明:执行过程中只有executor节点运行在集群,任务运行结束executor pod就被删除了,要查询任务执行记录可以通过history server或者driver log来查看。


4、使用-f执行SQL脚本

spark-test-sql.sql脚本内容:
USE default;
DROP TABLE IF EXISTS spark_dept;
CREATE TABLE spark_dept
(
deptno int,
dname string,
loc string
);
INSERT INTO spark_dept
VALUES (10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON'),
(50, 'DEVELOP', 'Washington');
SELECT * FROM spark_dept;
DROP TABLE IF EXISTS spark_emp;
CREATE TABLE spark_emp
(
EMPNO int,
ENAME string,
JOB string,
MGR double,
HIREDATE string,
SAL double,
COMM double,
DEPTNO int
);
INSERT INTO spark_emp
VALUES (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, NULL, 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1981-2-20', 1600, 300, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1981-2-22', 1250, 500, 30),
(7566, 'JONES', 'MANAGER', 7839, '1981-4-2', 2975, NULL, 20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1981-9-28', 1250, 1400, 30),
(7698, 'BLAKE', 'MANAGER', 7839, '1981-5-1', 2850, NULL, 30),
(7782, 'CLARK', 'MANAGER', 7839, '1981-6-9', 2450, NULL, 10),
(7788, 'SCOTT', 'ANALYST', 7566, '1987-4-19', 3000, NULL, 20),
(7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000, NULL, 10),
(7844, 'TURNER', 'SALESMAN', 7698, '1981-9-8', 1500, 0, 30),
(7876, 'ADAMS', 'CLERK', 7788, '1987-5-23', 1100, NULL, 20),
(7900, 'JAMES', 'CLERK', 7698, '1981-12-3', 950, NULL, 30),
(7902, 'FORD', 'ANALYST', 7566, '1981-12-3', 3000, NULL, 20),
(7934, 'MILLER', 'CLERK', 7782, '1982-1-23', 1300, NULL, 10);
SELECT * FROM spark_emp;
SELECT a.*, b.*
FROM spark_dept a,
spark_emp b
WHERE a.deptno = b.deptno
AND b.sal > 2100;
SELECT e.deptno, d.dname, SUM(sal) sum_sal, AVG(sal) avg_sal, MAX(sal) avg_sal, MIN(sal) avg_sal
FROM spark_emp e,
spark_dept d
WHERE e.deptno = d.deptno
GROUP BY e.deptno, d.dname;
SELECT deptno, SUM(sal)
FROM spark_emp
WHERE deptno > 10
GROUP BY deptno;
7.Spark Sql Hive 版本适配
在之前的测试中,我们使用hive 3.1.3 版本的metastore,但spark v3.2.3自带的hive客户端jar包版本是2.3.9,虽然在此前的测试中Spark SQL均能正常运行,但为了确保两者尽可能兼容,在实际的应用中建议统一hive的版本。
1、首先需要构建含有hive 3.1.3版本jar包的spark镜像
mkdir /root/my_dockerfile/spark-hive -p cd /root/my_dockerfile/spark-hive mkdir hive-lib cp /opt/module/hive/lib/*.jar hive-lib/
(2)编写Dockerfile
[root@k8s-demo001 spark-hive]# cat Dockerfile FROM apache/spark:v3.2.3 COPY hive-lib /opt/hive-lib WORKDIR /opt/spark/work-dir ENTRYPOINT ["/opt/entrypoint.sh"] USER 185
(3)构建镜像,并上传到镜像仓库
docker build -f Dockerfile -t spark-hive3:v3.2.3 . docker tag spark-hive3:v3.2.3 172.16.252.110:8011/sparkonk8s/spark-hive3:v3.2.3 docker push 172.16.252.110:8011/sparkonk8s/spark-hive3:v3.2.3
2、在spark-submit(driver)运行节点放置hive 客户端jar包,路径要与spark镜像里的路径一致
mkdir /opt/hive-lib cp /opt/module/hive-3.1.3/lib/*.jar /opt/hive-lib/
3、编写executor pod template
[root@k8s-demo001 ~]# cat /data/nginx_down/executor-sql-hadoop-hive3.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app.kubernetes.io/name: apache-spark
app.kubernetes.io/instance: apache-spark
app.kubernetes.io/version: v3.2.3
namespace: apache-spark
name: executor
spec:
serviceAccountName: spark-service-account
hostAliases:
- ip: "172.16.252.105"
hostnames:
- "k8s-demo001"
- ip: "172.16.252.134"
hostnames:
- "k8s-demo002"
- ip: "172.16.252.135"
hostnames:
- "k8s-demo003"
- ip: "172.16.252.136"
hostnames:
- "k8s-demo004"
containers:
- image: 172.16.252.110:8011/sparkonk8s/spark-hive3:v3.2.3
name: executor
imagePullPolicy: IfNotPresent
env:
- name: TZ
value: Asia/Shanghai
- name: HADOOP_USER_NAME
value: hadoop
- name: SPARK_USER
value: hadoop
- name: SPARK_LOCAL_DIRS # 设置shuffle落数的路径
value: "/opt/spark/shuffle-data"
resources:
requests:
cpu: 1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: spark-logs # 挂载日志
mountPath: /opt/spark/logs
- name: spark-shuffle # 挂载shuffle落数路径
mountPath: /opt/spark/shuffle-data
volumes:
- name: spark-logs
persistentVolumeClaim:
claimName: spark-logs-pvc
- name: spark-shuffle
persistentVolumeClaim:
claimName: spark-shuffle-pvc
4、提交spark sql测试
./spark-3.2.3-hadoop/bin/spark-submit \ --name spark-sql-hive3-1 \ --verbose \ --master k8s://https://172.16.252.105:6443 \ --deploy-mode client \ --conf spark.network.timeout=300 \ --conf spark.executor.instances=3 \ --conf spark.driver.cores=1 \ --conf spark.executor.cores=1 \ --conf spark.driver.memory=1024m \ --conf spark.executor.memory=1024m \ --conf spark.driver.host=k8s-demo001 \ --conf spark.sql.hive.metastore.version=3.1.3 \ --conf spark.sql.hive.metastore.jars=/opt/hive-lib/* \ --conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/driver-sql-hadoop-hive3-1.log" \ --conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/executor-sql-hadoop-hive3-1.log" \ --conf spark.eventLog.enabled=true \ --conf spark.eventLog.dir=hdfs://hadoop-test01:8020/spark/eventLog \ --conf spark.history.fs.logDirectory=hdfs://hadoop-test01:8020/spark/eventLog \ --conf spark.kubernetes.namespace=apache-spark \ --conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \ --conf spark.kubernetes.container.image=172.16.252.110:8011/sparkonk8s/spark-hive3:v3.2.3 \ --conf spark.kubernetes.executor.podTemplateFile=http://172.16.252.105:8080/executor-sql-hadoop-hive3.yaml \ --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver \ -e \ " DROP TABLE IF EXISTS spark_dept; CREATE TABLE spark_dept(deptno int, dname string, loc string); INSERT INTO spark_dept VALUES (10, 'ACCOUNTING', 'NEW YORK'); select * from spark_dept; select count(*) from spark_dept where deptno=10 "
转载请注明:西门飞冰的博客 » (6)Spark Sql on K8S 实现



