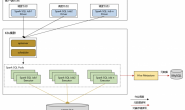
1.简介
flink native k8s就是使用flink 自有的命令来提交作业到k8s集群的,需要提前下载好flink安装包
实际生产中使用flink on k8s推荐使用flink kubernetes operator的方式,flink native k8s还不是很成熟,坑略多。
2.环境初始化
实际工作中,为了规范flink 作业在k8s上的运行部署,通常会讲flink 作业调度到指定的namespace中运行,并使用特定的ServiceAccount运行。
注:在flink kubernetes operator下,role、ClusterRole、RoleBinding等资源会自动创建,但是在native模式下需要我们手动进行创建这些资源。
1、创建namespace
kubectl create namespace apache-flink
2、创建service-account
kubectl create serviceaccount flink-service-account -n apache-flink
3、创建Role和RoleBinding
[root@k8s-demo001 ~]# cat role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app.kubernetes.io/name: apache-flink
app.kubernetes.io/instance: apache-flink
namespace: apache-flink
name: flink-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list", "create", "delete"]
- apiGroups: ["extensions", "apps"]
resources: ["deployments"]
verbs: ["get", "watch", "list", "create", "delete"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "create", "update", "delete"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
- apiGroups: [""]
resources: ["services"]
verbs: ["get", "list", "create", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
app.kubernetes.io/name: apache-flink
app.kubernetes.io/instance: apache-flink
name: flink-role-binding
namespace: apache-flink
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: flink-role
subjects:
- kind: ServiceAccount
name: flink-service-account
namespace: apache-flink
[root@k8s-demo001 ~]# kubectl apply -f role.yaml
4、创建ClusterRole和ClusterRoleBinding
[root@k8s-demo001 ~]# cat cluster-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/name: apache-flink
app.kubernetes.io/instance: apache-flink
name: apache-flink-clusterrole
rules:
- apiGroups:
- ''
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
- namespaces
verbs:
- list
- watch
- get
- apiGroups:
- ''
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- events
verbs:
- create
- patch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/name: apache-flink
app.kubernetes.io/instance: apache-flink
name: apache-flink-clusterrole-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: apache-flink-clusterrole
subjects:
- kind: ServiceAccount
name: flink-service-account
namespace: apache-flink
[root@k8s-demo001 ~]# kubectl apply -f cluster-role.yaml
3.
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.log4j.Logger;
import java.util.Arrays;
public class StreamWordCount {
private static Logger logger = Logger.getLogger(StreamWordCount.class);
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流 在k8s01行运行 nc -lk 7777
DataStreamSource<String> lineDSS = env.socketTextStream("172.16.252.105", 7777);
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
logger.info(result.toString());
// 7. 执行
env.execute();
}
}
4.Session 模式测试
1、安装flink
wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.12.tgz tar xf flink-1.13.6-bin-scala_2.12.tgz
2、启动flink session集群
#注意,在1.13.x-1.16.x要使用kubernetes.container.image指定镜像
#1.17使用kubernetes.container.image.ref
./flink-1.13.6/bin/kubernetes-session.sh \ -Dkubernetes.cluster-id=session-deployment-only \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account \ -Dkubernetes.container.image="flink:1.13.6" \ -Dkubernetes.container.image.pull-policy="IfNotPresent" \ -Dkubernetes.rest-service.exposed.type="NodePort"
验证集群启动情况
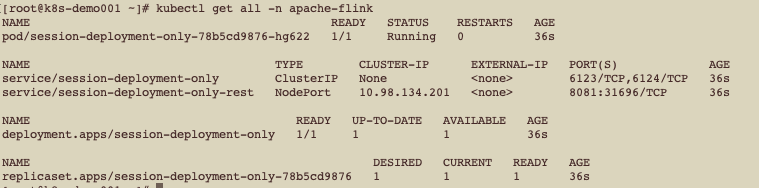
访问web ui测试
3、在172.16.252.105 服务器运行nc监听在7777端口,不然一会提交作业会报错
nc -lk 7777
4、提交作业到集群,注意这里使用的是读取本地jar包的方式,并且只能使用local方式获取flink作业的jar包,提交命令是flink不是kubernetes-session
./flink-1.13.6/bin/flink run \ --target kubernetes-session \ -Dkubernetes.cluster-id=session-deployment-only \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account \ -c org.fblinux.StreamWordCount \ /root/flink-on-k8s-demo-1.0-SNAPSHOT.jar
5、往nc发送字符内容,观察taskmanager日志输出
kubectl logs pod/session-deployment-only-taskmanager-1-1 -n apache-flink
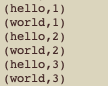
6、查看作业列表
./flink-1.13.6/bin/flink list \ --target kubernetes-session \ -Dkubernetes.cluster-id=session-deployment-only \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account
7、终止集群
只是删除作业,不会删除jobmanager
./flink-1.13.6/bin/flink cancel \ --target kubernetes-session \ -Dkubernetes.cluster-id=session-deployment-only \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account \ 126e0ec61ee53c2187e1dd89ae12b34c
彻底删除集群
kubectl delete deployment session-deployment-only -n apache-flink
5.Application 模式测试
1、提交作业
注:在native k8s下,Application模式,只能使用local方式获取Flink作业Jar包
./flink-1.13.6/bin/flink run-application \ --target kubernetes-application \ -Dkubernetes.cluster-id=application-deployment \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account \ -Dkubernetes.container.image=172.16.252.110:8011/flinkonk8s/flink-wc:1.13.6 \ -Dkubernetes.container.image.pull-policy="IfNotPresent" \ -Dkubernetes.rest-service.exposed.type="NodePort" \ -c org.fblinux.StreamWordCount \ local:///opt/flink/flink-on-k8s-demo-1.0-SNAPSHOT.jar
2、往nc发送字符内容,观察taskmanager日志输出
3、查看作业列表
./flink-1.13.6/bin/flink list \ --target kubernetes-application \ -Dkubernetes.cluster-id=application-deployment \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account
4、终止集群
通过flink 命令终止:
./flink-1.13.6/bin/flink cancel \ --target kubernetes-application \ -Dkubernetes.cluster-id=application-deployment \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account \ 8cb17cc033b440b98c4049e2113bc3df
通过k8s命令终止:
kubectl delete deployment application-deployment -n apache-flink
6.Pod Template提交任务
在前面的示例中都是通过命令行传参的方式来配置flink相关的参数,这些参数既有控制flink运行的又有k8s相关的。但是和k8s原生的配置flink 命令行并不能完全支持,例如挂载卷等。针对这种情况,flink 官方支持使用pod template 定义jobmanager和taskmaster的pod信息,在pod template里面可以使用k8s原生支持的语法,这样不仅可以极大的简化flink命令行的参数数量,而且还可以在pod template里面添加flink所不能支持的配置项。
如果同一个配置在命令行和pod template里面都有定义,那么命令行的优先级是最高的。
这里使用之前的flink checkpoint程序来测试pod template提交任务。
1、创建pvc
[root@k8s-demo001 ~]# cat flink-jar-pvc.yaml
# Flink jar 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-jar-pvc # jar pvc名称
namespace: apache-flink # 指定归属的名命空间
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
创建存储checkpoint的pvc
[root@k8s-demo001 ~]# cat flink-checkpoint-pvc.yaml
# Flink checkpoint 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-checkpoint-pvc # checkpoint pvc名称
namespace: apache-flink # 指定归属的名命空间
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
创建存储log的pvc
[root@k8s-demo001 ~]# cat flink-log-pvc.yaml
# Flink log 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-log-pvc # log pvc名称
namespace: apache-flink # 指定归属的名命空间
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
创建ha的pvc
[root@k8s-demo001 ~]# cat flink-ha-pvc.yaml
# Flink ha 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-ha-pvc # ha pvc名称
namespace: apache-flink # 指定归属的名命空间
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
2、编写pod template
[root@ansible ~]# cat flink-pod-template.yaml
apiVersion: v1
kind: Pod
metadata:
name: flink-pod-template
namespace: apache-flink
spec:
hostAliases:
- ip: "172.16.252.129"
hostnames:
- "es-01"
- ip: "172.16.252.130"
hostnames:
- "es-02"
- ip: "172.16.252.131"
hostnames:
- "es-03"
containers:
# Do not change the main container name
- name: flink-main-container
image: flink:1.13.6
imagePullPolicy: IfNotPresent
env:
- name: TZ
value: Asia/Shanghai
resources:
requests:
cpu: 1
memory: 1024mb
limits:
cpu: 1
memory: 1024mb
volumeMounts:
- name: flink-jar # 挂载nfs上的jar
mountPath: /opt/flink/jar
- name: flink-checkpoints # 挂载checkpoint pvc
mountPath: /opt/flink/checkpoints
- name: flink-log # 挂载日志 pvc
mountPath: /opt/flink/log
- name: flink-ha # HA pvc配置
mountPath: /opt/flink/flink_recovery
volumes:
- name: flink-jar
persistentVolumeClaim:
claimName: flink-jar-pvc
- name: flink-checkpoints
persistentVolumeClaim:
claimName: flink-checkpoint-pvc
- name: flink-log
persistentVolumeClaim:
claimName: flink-log-pvc
- name: flink-ha
persistentVolumeClaim:
claimName: flink-ha-pvc
3、提交flink 作业
./flink-1.13.6/bin/flink run-application \ --target kubernetes-application \ -Dkubernetes.cluster-id=application-pod-template-1 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dstate.checkpoints.dir=file:///opt/flink/checkpoints \ -Dhigh-availability=ZOOKEEPER \ -Dhigh-availability.zookeeper.quorum=172.16.252.129:2181,172.16.252.130:2181,172.16.252.131:2181 \ -Dhigh-availability.zookeeper.path.root=/flink \ -Dhigh-availability.storageDir=file:///opt/flink/flink_recovery \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account \ -Dkubernetes.rest-service.exposed.type="NodePort" \ -Dkubernetes.pod-template-file.jobmanager=/root/flink-native-yaml/flink-pod-template.yaml \ -Dkubernetes.pod-template-file.taskmanager=/root/flink-native-yaml/flink-pod-template.yaml \ -Dkubernetes.jobmanager.replicas=2 \ --class org.fblinux.StreamWordCountWithCP \ local:///opt/flink/jar/flink-on-k8s-demo-1.0-SNAPSHOT-jar-with-dependencies.jar \ "172.16.252.129:9092,172.16.252.130:9092,172.16.252.131:9092" "flink_test" "172.16.252.113" "3306" "flink_test" "wc" "file:///opt/flink/checkpoints" "10000" "1"
4、观察jobmanager和taskmanager pod
watch -n 1 kubectl get all -owide -n apache-flink
查看作业列表
./flink-1.13.6/bin/flink list \ --target kubernetes-application \ -Dkubernetes.cluster-id=application-pod-template-1 \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account
5、往kafka发送字符串数据,验证mysql 表能否正常收到写入内容
6、终止集群
(1)高可用场景下,使用flink cancel命令终止作业,zk上的作业的高可用信息会被清除,也就是checkpoint信息也会被清除,下次启动作业不会从checkpoint恢复
./flink-1.13.6/bin/flink cancel \ --target kubernetes-application \ -Dkubernetes.cluster-id=application-pod-template-1 \ -Dkubernetes.namespace=apache-flink \ -Dkubernetes.service-account=flink-service-account \ 00000000000000000000000000000000
(2)高可用场景下,用kubectl delete终止作业,作业的高可用信息仍然保存在zk上,下次启动会从上一次的checkpoint恢复
kubectl delete deployment application-pod-template-1 -n apache-flink
转载请注明:西门飞冰的博客 » (7)Flink Native K8S