1.简介
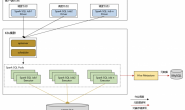
Spark Shuffle通常是在RDD宽依赖的情况下发生,是上游Stage和下游Stage之间传递数据的一种机制。shuffle阶段通常会伴随中间数据的落盘(数据量不大的情况下也可以不落盘而是全部保存在内存中),shuffle的性能高低直接影响了整个Spark程序的性能和吞吐量,尤其是处理大量数据的时候尤为显著。
当有大量中间结果数据需要Shuffle时,数据要落盘是必然的。
在Spark On K8s环境下,Spark默认使用Pod容器的文件系统来保存Shuffle落数,此方式消耗的是K8s Node节点的存储空间,在数据量小的时候这样做没有问题,但当Spark程序需要处理上百GB或上TB数据的时候,Shuffle需要落数的数据量就会很大,为了应对这种场景,实际的应用中通常需要使用高性能的存储,用于shuffle的落数,这里的高性能的存储通常是SSD的云盘,采用pv+pvc的方式,挂载到spark的pod容器里面,而不是保存在容器里的文件系统中。
2.配置PVC 落盘
1、创建ShufflePVC
[root@k8s-demo001 ~]# cat spark-shuffle-pvc.yaml
# Spark Shuffle 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: spark-shuffle-pvc # shuffle pvc名称
namespace: apache-spark
spec:
storageClassName: nfs-storage #sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 5Gi #存储容量,根据实际需要更改
[root@k8s-demo001 ~]# kubectl apply -f spark-shuffle-pvc.yaml
2、创建pod template
[root@k8s-demo001 ~]# cat /data/nginx_down/executor-sql-hadoop-shuffle.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app.kubernetes.io/name: apache-spark
app.kubernetes.io/instance: apache-spark
app.kubernetes.io/version: v3.2.3
namespace: apache-spark
name: executor
spec:
serviceAccountName: spark-service-account
hostAliases:
- ip: "172.16.252.105"
hostnames:
- "k8s-demo001"
- ip: "172.16.252.134"
hostnames:
- "k8s-demo002"
- ip: "172.16.252.135"
hostnames:
- "k8s-demo003"
- ip: "172.16.252.136"
hostnames:
- "k8s-demo004"
containers:
- image: apache/spark:v3.2.3
name: executor
imagePullPolicy: IfNotPresent
env:
- name: TZ
value: Asia/Shanghai
- name: HADOOP_USER_NAME
value: hadoop
- name: SPARK_USER
value: hadoop
- name: SPARK_LOCAL_DIRS # 设置shuffle落数的路径
value: "/opt/spark/shuffle-data"
resources:
requests:
cpu: 1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: spark-logs
mountPath: /opt/spark/logs
- name: spark-shuffle # 挂载shuffle落数路径
mountPath: /opt/spark/shuffle-data
volumes:
- name: spark-logs
persistentVolumeClaim:
claimName: spark-logs-pvc
- name: spark-shuffle
persistentVolumeClaim:
claimName: spark-shuffle-pvc
3、提交spark SQL
./spark-3.2.3-hadoop/bin/spark-submit \
--name spark-sql-shuffle-test-2 \
--verbose \
--master k8s://https://172.16.252.105:6443 \
--deploy-mode client \
--conf spark.network.timeout=300 \
--conf spark.executor.instances=3 \
--conf spark.driver.cores=1 \
--conf spark.executor.cores=1 \
--conf spark.driver.memory=1024m \
--conf spark.executor.memory=1024m \
--conf spark.driver.host=k8s-demo001 \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/driver-sql-shuffle-2.log" \
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/executor-sql-shuffle-2.log" \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=hdfs://hadoop-test01:8020/spark/eventLog \
--conf spark.history.fs.logDirectory=hdfs://hadoop-test01:8020/spark/eventLog \
--conf spark.kubernetes.namespace=apache-spark \
--conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \
--conf spark.kubernetes.container.image=apache/spark:v3.2.3 \
--conf spark.kubernetes.executor.podTemplateFile=http://172.16.252.105:8080/executor-sql-hadoop-shuffle.yaml \
--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver \
-e \
"
SELECT d.deptno, d.dname, SUM(sal) sum_sal, AVG(sal) avg_sal, MAX(sal) avg_sal, MIN(sal) avg_sal
FROM spark_emp e,
spark_dept d
WHERE e.deptno = d.deptno
GROUP BY d.deptno, d.dname;
"
3.将shuffle数据存在内存
仅适合数据量不大,且K8s能分配足够多的内存给Spark程序运行的场景
通过配置
./spark-3.2.3-hadoop/bin/spark-submit \
--name spark-sql-shuffle-test-3 \
--verbose \
--master k8s://https://172.16.252.105:6443 \
--deploy-mode client \
--conf spark.network.timeout=300 \
--conf spark.executor.instances=3 \
--conf spark.driver.cores=1 \
--conf spark.executor.cores=1 \
--conf spark.driver.memory=1024m \
--conf spark.executor.memory=1024m \
--conf spark.driver.host=k8s-demo001 \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/driver-sql-shuffle-3.log" \
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/executor-sql-shuffle-3.log" \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=hdfs://hadoop-test01:8020/spark/eventLog \
--conf spark.history.fs.logDirectory=hdfs://hadoop-test01:8020/spark/eventLog \
--conf spark.kubernetes.namespace=apache-spark \
--conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \
--conf spark.kubernetes.container.image=apache/spark:v3.2.3 \
--conf spark.kubernetes.executor.podTemplateFile=http://172.16.252.105:8080/executor-sql-hadoop.yaml \
--conf spark.kubernetes.local.dirs.tmpfs=true \
--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver \
-e \
"
SELECT d.deptno, d.dname, SUM(sal) sum_sal, AVG(sal) avg_sal, MAX(sal) avg_sal, MIN(sal) avg_sal
FROM spark_emp e,
spark_dept d
WHERE e.deptno = d.deptno
GROUP BY d.deptno, d.dname;
"