1.介绍
一般情况下,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量被复制到每台机器上,并且这些变量在远程机器上 的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
2.累加器
累加器:分布式共享只写变量。(Executor和Executor之间不能读数据)。
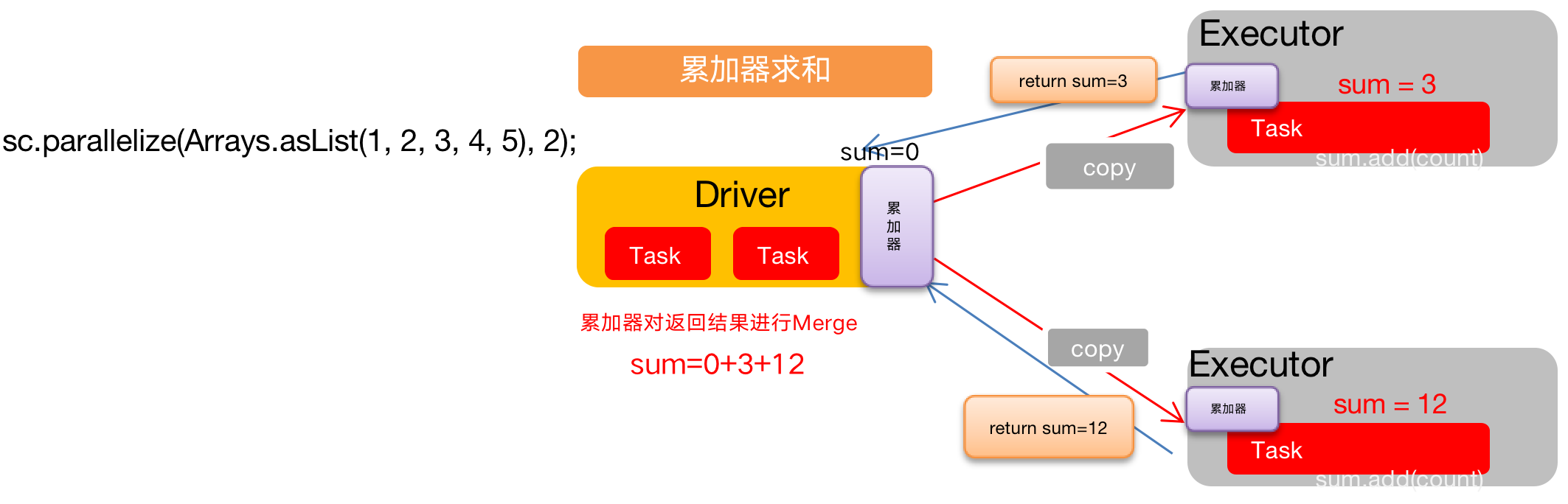
累加器用来把Executor端变量信息聚合到Driver端。在Driver中定义的一个变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行合并计算。
2.1.累加器原理
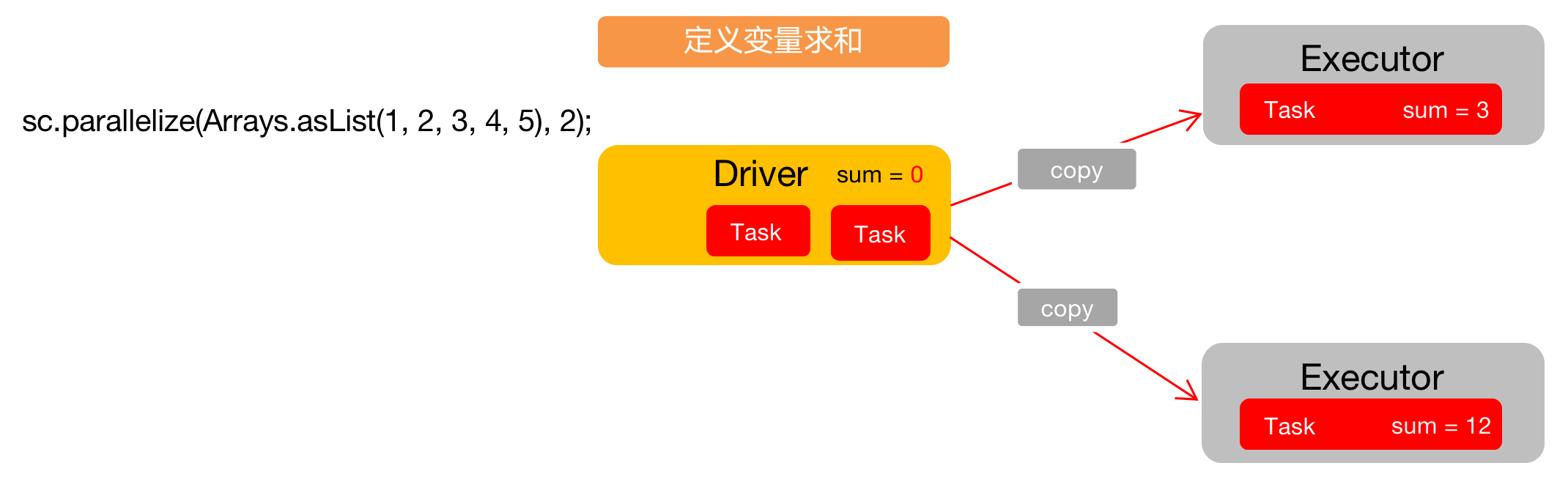
未使用累加器的场合:
在Spark中,如果想要在计算过程中共享变量,直接在driver中声明是不起作用的,因为Spark不会将这个变量在计算节点中传递。
使用累加器的场合:
累加器是Spark提供的一种共享数据的处理方式,也就意味着如果在Spark计算中共享数据,必须遵循Spark的规则,然后由Spark在计算节点中进行传递
2.2.累加器使用
(1)累加器定义(SparkContext.accumulator(initialValue)方法)
LongAccumulator acc = JavaSparkContext.toSparkContext(sc).longAccumulator();
(2)累加器添加数据(累加器.add方法)
cc.add(v1);
(3)累加器获取数据(累加器.value)
acc.value();
注意:Executor端的任务不能读取累加器的值(例如:在Executor端调用sum.value,获取的值不是累加器最终的值)。因此我们说,累加器是一个分布式共享只写变量。
累加器要放在行动算子中
因为转换算子执行的次数取决于job的数量,如果一个spark应用有多个行动算子,那么转换算子中的累加器可能会发生不止一次更新,导致结果错误。所以,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动算子中。
2.3.累加器使用示例代码
使用累加器实现基础的求和操作
public class Acc {
public static void main(String[] args) {
// 1 创建SparkConf
SparkConf sparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[2]");
// 2 创建SparkContext
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// 创建一个累加器,不同的数据类型选择不同类型的累加器
LongAccumulator acc = JavaSparkContext.toSparkContext(sc).longAccumulator();
// 3 编写代码
// 从集合创建一组数据,并配置两个以上分区
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5), 2);
// 通过map 算子遍历所有数据,并通过累加器add方法求和
JavaRDD<Integer> map = javaRDD.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
acc.add(v1);
//System.out.println(acc.value());
return v1;
}
});
map.collect();
System.out.println("输出累加器计算后的结果");
System.out.println(acc.value());
// 4 关闭资源
sc.stop();
}
}
累加器结合foreach
累加器最好的使用方式就是结合foreach使用,因为别的行动算子没有办法自定义逻辑,foreach就相当于一个自定义的行动算子,可以在里面自己写逻辑,累加器加foreach可以实现解耦的效果,把累加器拆解开来使用。
public class Acc_foreach {
public static void main(String[] args) {
// 1 创建SparkConf
SparkConf sparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[2]");
// 2 创建SparkContext
JavaSparkContext sc = new JavaSparkContext(sparkConf);
LongAccumulator acc = JavaSparkContext.toSparkContext(sc).longAccumulator();
LongAccumulator acc2 = JavaSparkContext.toSparkContext(sc).longAccumulator();
// 3 编写代码
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5), 2);
JavaRDD<Integer> map = javaRDD.map(x -> x);
map.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
acc.add(integer);
}
});
map.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
acc2.add(integer);
}
});
System.out.println(acc.value());
System.out.println(acc2.value());
// 4 关闭资源
sc.stop();
}
}
3.广播变量
广播变量:分布式共享只读变量。
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark Task操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来会很顺手。在多个Task并行操作中使用同一个变量,但是Spark会为每个Task任务分别发送。
在可接受的范围内,变量越大,越需要广播! 在能广播的前提下,待广播的数据量越大,提升效率越明显。内存资源占用的减小很明显
如果待广播特别小,就没有广播的必要性了。
3.1.广播变量原理
如果使用广播变量的工作机制,则一个worker中启动的某个executor中的多个Task 就可以共用一份数据,这个广播数据就是存储在 存储内存中,这个内存有可能是堆内内存,也有可能是堆外内存

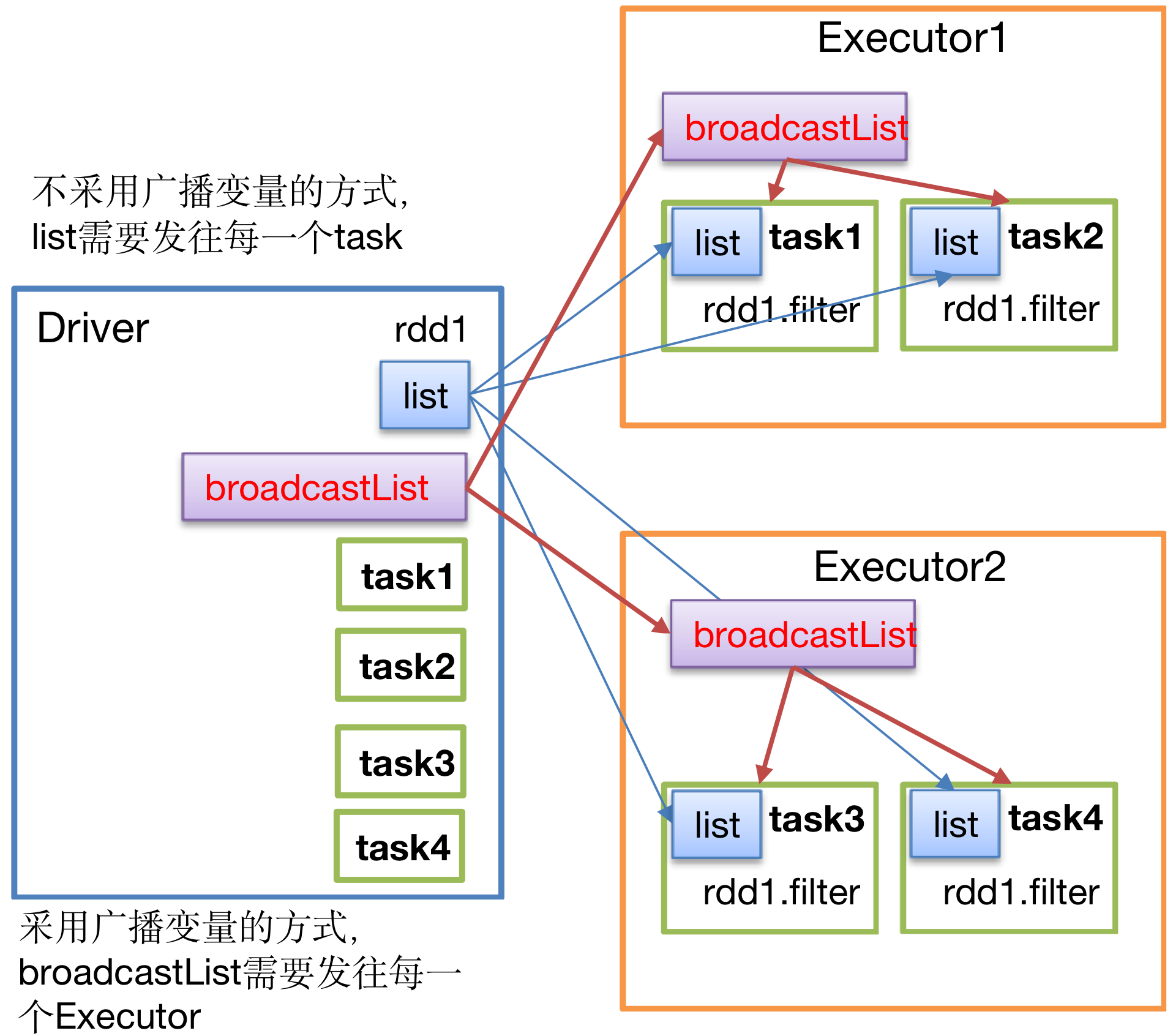
3.2.广播变量使用
(1)调用SparkContext.broadcast(广播变量)创建出一个广播对象,任何可序列化的类型都可以这么实现。
(2)通过广播变量.value,访问该对象的值。
(3)广播变量只会被发到各个节点一次,作为只读值处理(修改这个值不会影响到别的节点)。
3.3.代码示例
使用Spark Core模拟一个抽奖的小程序:
public class Broadcost {
public static void main(String[] args) {
// 1 创建SparkConf
SparkConf sparkConf = new SparkConf().setAppName("SparkCore").setMaster("local[2]");
// 2 创建SparkContext
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// 3 编写代码
// 定义中奖的数据
List<Integer> list = Arrays.asList(5, 6, 7);
// 定义广播变量(分布式只读变量)
Broadcast<List<Integer>> broadcast = sc.broadcast(list);
// 定义抽奖的奖池
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(2, 6, 4, 9, 10, 3, 7, 8), 4);
JavaRDD<Integer> filter = javaRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer v1) throws Exception {
List<Integer> value = broadcast.value();
// 判断list集合是否包含v1,包含则返回
return value.contains(v1);
}
});
filter.collect().forEach(System.out::println);
// 4 关闭资源
sc.stop();
}
}
Broadcast与map进行无shuffle join代码示例:
// 传统的join操作会导致shuffle操作。 // 因为两个RDD中,相同的key都需要通过网络拉取到一个节点上,由一个task进行join操作。 val rdd3 = rdd1.join(rdd2) // Broadcast+map的join操作,不会导致shuffle操作。 // 使用Broadcast将一个数据量较小的RDD作为广播变量。 val rdd2Data = rdd2.collect() val rdd2DataBroadcast = sc.broadcast(rdd2Data) // 在rdd1.map算子中,可以从rdd2DataBroadcast中,获取rdd2的所有数据。 // 然后进行遍历,如果发现rdd2中某条数据的key与rdd1的当前数据的key是相同的,那么就判定可以进行join。 // 此时就可以根据自己需要的方式,将rdd1当前数据与rdd2中可以连接的数据,拼接在一起(String或Tuple)。 val rdd3 = rdd1.map(rdd2DataBroadcast...) // 注意,以上操作,建议仅仅在rdd2的数据量比较少(比如几百M,或者一两G)的情况下使用。 // 因为每个Executor的内存中,都会驻留一份rdd2的全量数据。
转载请注明:西门飞冰的博客 » Spark RDD 共享变量