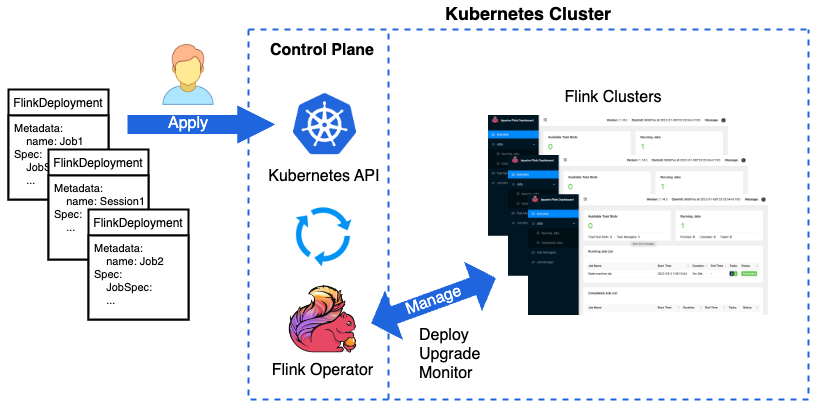
1.简介
Flink Kubernetes Operator是一个用于在Kubernetes集群上部署、管理和自动化运行Apache Flink应用程序的开源项目。它提供了一种简单、可靠且可扩展的方式来部署和管理Flink作业,同时实现高可用性和容错性。
Flink Kubernetes Operator的主要优势包括:
1、自动化部署:Flink Kubernetes Operator 可以自动部署和管理 Flink 集群以及在集群上运行的作业。
2、弹性伸缩:Flink Kubernetes Operator 可以自动扩展和收缩 Flink 集群,根据作业的负载情况来调整集群的大小。
3、更好的资源利用率:使用 Kubernetes 的资源管理功能,可以更好地利用集群资源,提高资源利用率。
Flink Kubernetes Operator的主要缺点包括:
1、学习成本:使用 Flink Kubernetes Operator 需要一定的 Kubernetes 和 Flink 的知识储备,对于初学者来说可能会有一定的学习成本。
总体来说,Flink Kubernetes Operator是一个非常有用的工具,适用于那些需要将Flink应用程序部署到复杂的Kubernetes集群中的用户。其优势在于提供了简单的部署和高可用性,并且可以根据需要扩展资源,但其缺点在于需要一定的学习成本和配置复杂度较高。
2.Flink k8s Operator安装
1、安装helm
[root@k8s-demo001 ~]# tar xf helm-v3.8.2-linux-amd64.tar.gz [root@k8s-demo001 ~]# mv linux-amd64/helm /usr/local/bin/
2、添加常用的helm 源
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.4.0/ helm repo add stable http://mirror.azure.cn/kubernetes/charts helm repo add bitnami https://charts.bitnami.com/bitnami helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
wget https://github.com/jetstack/cert-manager/releases/download/v1.10.0/cert-manager.yaml kubectl apply -f cert-manager.yaml
要是因为网络问题拉取不了cert-manager的镜像,需要手动替换为国内的镜像地址:
image: "registry.cn-hangzhou.aliyuncs.com/cm_ns01/cert-manager-cainjector:v1.10.0" image: "registry.cn-hangzhou.aliyuncs.com/cm_ns01/cert-manager-controller:v1.10.0" image: "registry.cn-hangzhou.aliyuncs.com/cm_ns01/cert-manager-webhook:v1.10.0"

4、安装Flink Kubernetes Operator
使用helm本地安装,这种方式可以定制flink operator的配置,我们采用此方式
从官网下载flink-kubernetes-operator heml包
wget https://downloads.apache.org/flink/flink-kubernetes-operator-1.4.0/flink-kubernetes-operator-1.4.0-helm.tgz tar xf flink-kubernetes-operator-1.4.0-helm.tgz
如果担心网络原因拉取不了flink operator的镜像,则修改flink operator helm目录下的values.yaml文件,修改repository地址
repository: registry.cn-hangzhou.aliyuncs.com/cm_ns01/flink-kubernetes-operator
安装:
helm install -f values.yaml flink-kubernetes-operator . --namespace flink --create-namespace

3.Flink on K8S 运行模式
flink 在k8s上运行,有session模式和application模式,区别主要在生命周期和资源隔离程度,如下所述:
Application模式:
1、为每个提交的Flink 作业创建一个Flink 集群(JobManager + TaskManager),并在作业运行完成时终止并释放全部Pod
2、Application 模式在不同作业之间提供了资源隔离和负载平衡保证,作业间彼此独立,互不影响。
Session模式:
1、需要先在K8S上启动一个集群(初始集群只有Job Manager,没有TaskManager),客户端向该集群提交作业,K8S 为每个作业动态创建TaskManager,Task Manager的数量由每个作业所需的计算资源量决定,所有作业共享一个Job Manager,作业终止Task Manager Pod释放,但Job Manager继续运行。
2、因为所有作业共享一个Job Manager,所以作业的资源隔离较差,作业间存在相互影响。
4.flink on K8S 测试程序
开发一个word count程序,用于提交k8s 进行测试,功能实现为从socket读取字符流,同级单词出现的次数,并将统计结果打印到控制台
flink 主程序:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.log4j.Logger;
import java.util.Arrays;
public class StreamWordCount {
private static Logger logger = Logger.getLogger(StreamWordCount.class);
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流 在k8s01行运行 nc -lk 7777
DataStreamSource<String> lineDSS = env.socketTextStream("172.16.252.105", 7777);
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
logger.info(result.toString());
// 7. 执行
env.execute();
}
}
log4j.properties
log4j.rootLogger=error, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
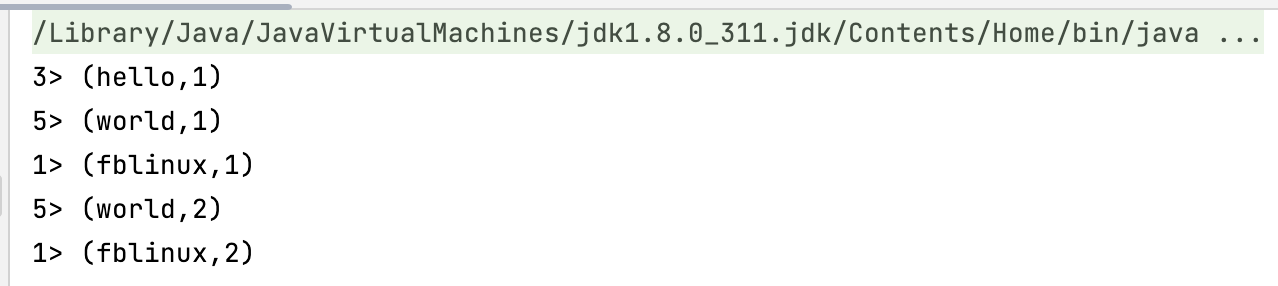
本地测试:
在172.16.252.105服务器安装nc,并监听在7777端口,启动flink程序,监听输入的内容并统计

5.Session 模式测试
5.1.手动上传jar包
1、创建session集群
[root@k8s-demo001 ~]# cat session-deployment-only.yaml
# Flink Session集群
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: session-deployment-only
spec:
image: flink:1.13.6
flinkVersion: v1_13
imagePullPolicy: IfNotPresent # 镜像拉取策略,本地没有则从仓库拉取
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io/{{namespace}}/{{name}}(/|$)(.*)"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/$2"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink
jobManager: # jobManager 配置
replicas: 1
resource:
memory: "1024m"
cpu: 1
taskManager: # taskManager配置
replicas: 1
resource:
memory: "1024m"
cpu: 1
[root@k8s-demo001 ~]# kubectl apply -f session-deployment-only.yaml
2、访问flink session集群
配置hosts域名解析
172.16.252.105 flink.k8s.io
访问Flink UI:http://flink.k8s.io/flink/session-deployment-only/#/overview
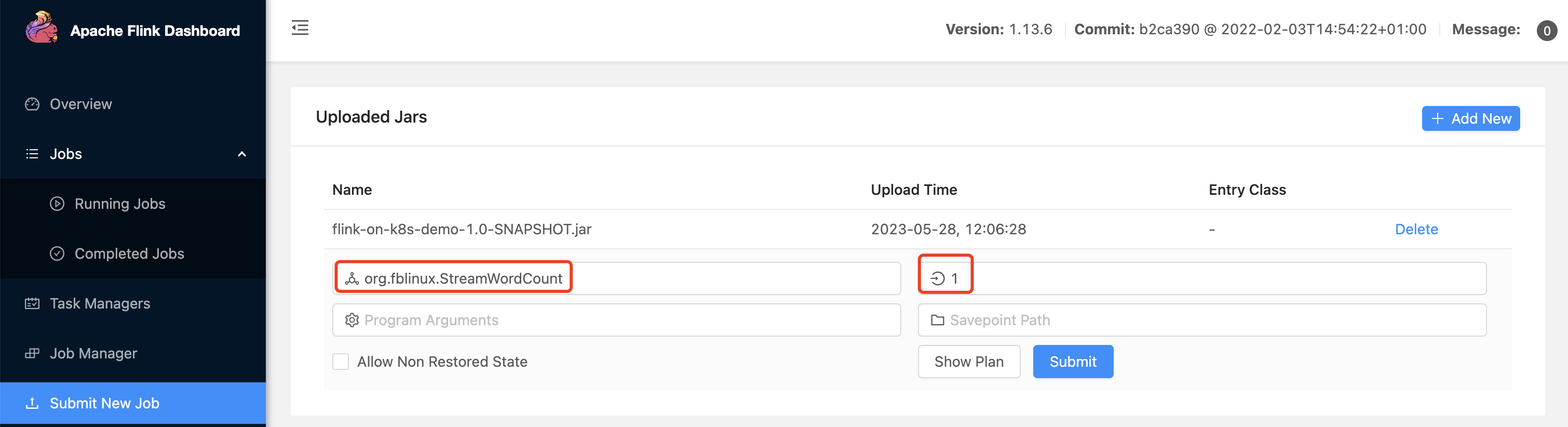
上传Jar包,提交作业:

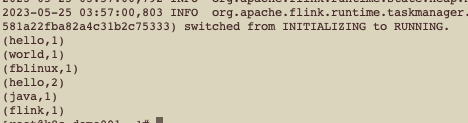
通过nc传入数据,查询K8S 日志:
kubectl logs session-deployment-only-taskmanager-1-1 -n flink
5.2.使用http下载jar包
1、通过nginx 搭建一个文件服务器,并将flink 编译完成的jar包上传上去
[root@k8s-demo001 ~]# cat session-job-only.yaml
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
namespace: flink
name: session-job-only
spec:
deploymentName: session-deployment-only # 需要与创建的集群名称一致
job:
jarURI: http://172.16.252.106:8090/flink-on-k8s-demo-1.0-SNAPSHOT.jar # 使用http方式下载jar包
entryClass: org.fblinux.StreamWordCount
args:
parallelism: 1 # 并行度
upgradeMode: stateless
[root@k8s-demo001 ~]# kubectl apply -f session-job-only.yaml

访问Flink UI:http://flink.k8s.io/flink/session-deployment-only/#/overview
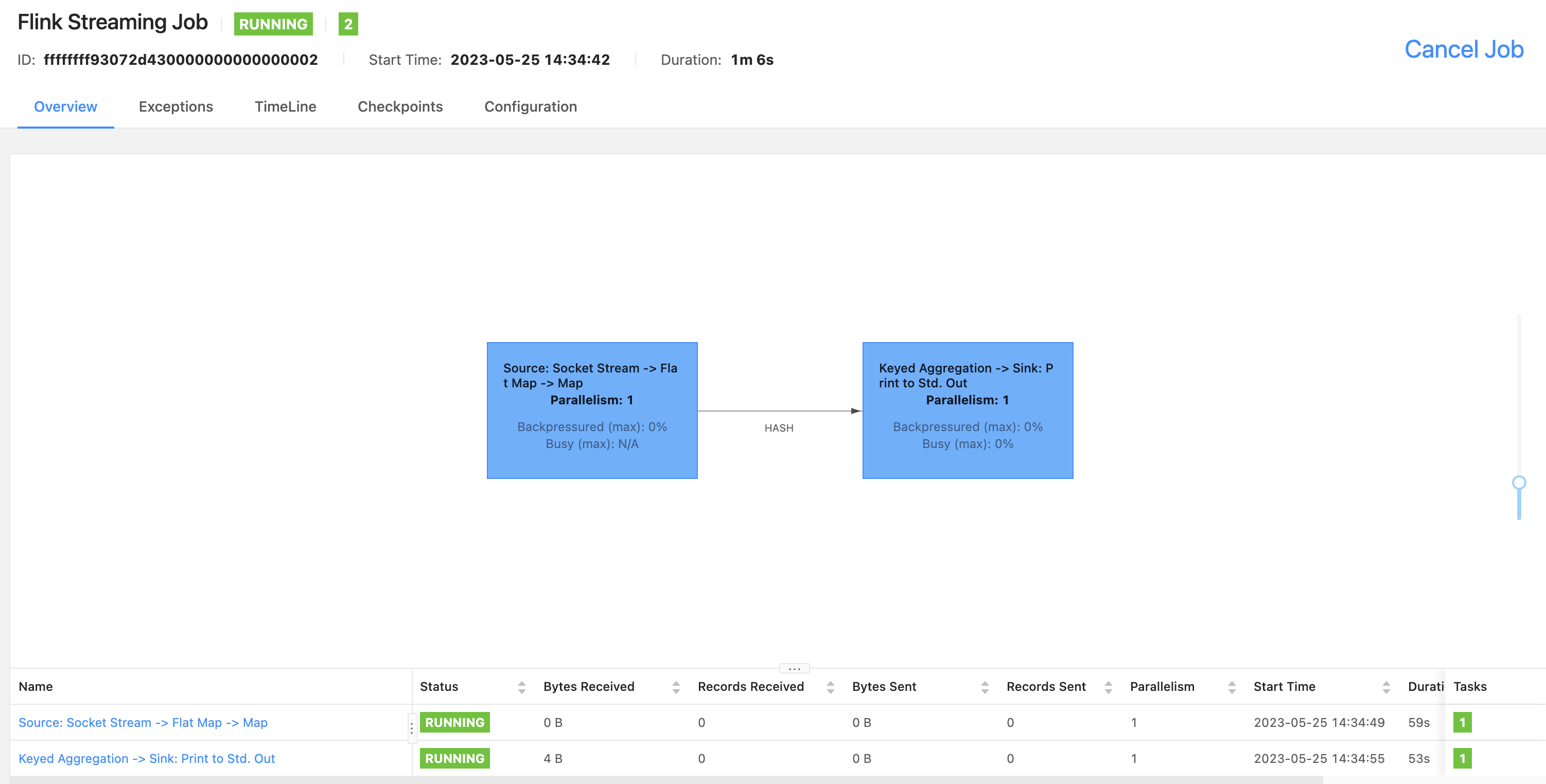
6.Application 模式测试
Application 模式作业的提交方式也有两种:
方式1:将作业jar包打进flink镜像,在编写flink deployment文件的时候,引用这个镜像,当flink 集群创建出来的时候,内部就会自然包含作业的jar包,这种方式就是每个作业都要创建自己专属的镜像,就会导致镜像过多,占用大量的空间
(1)编写Dockerfile构建镜像
[root@k8s-demo001 flink-wc]# cat Dockerfile FROM flink:1.13.6 WORKDIR /opt/flink COPY flink-on-k8s-demo-1.0-SNAPSHOT.jar /opt/flink/flink-on-k8s-demo-1.0-SNAPSHOT.jar ENTRYPOINT ["/docker-entrypoint.sh"] EXPOSE 6123 8081 CMD ["help"]
上传jar包到和Dockerfile同级目录,执行如下命令进行镜像的构建
docker build -f Dockerfile -t flink-wc:1.13.6 .
将构建的镜像上传到harbor,这样k8s部署的节点才能下载到镜像文件
docker tag flink-wc:1.13.6 172.16.252.110:8011/flinkonk8s/flink-wc:1.13.6 docker push 172.16.252.110:8011/flinkonk8s/flink-wc:1.13.6
(2)编写作业application-deployment.yaml,并提交
[root@k8s-demo001 ~]# cat application-deployment.yaml
# Flink Application集群
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: application-deployment
spec:
image: 172.16.252.110:8011/flinkonk8s/flink-wc:1.13.6 # 镜像存储在harbor仓库的地址
flinkVersion: v1_13
imagePullPolicy: IfNotPresent # 镜像拉取策略,本地没有则从仓库拉取
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io/{{namespace}}/{{name}}(/|$)(.*)"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/$2"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink
jobManager:
replicas: 1
resource:
memory: "1024m"
cpu: 1
taskManager:
replicas: 1
resource:
memory: "1024m"
cpu: 1
job:
jarURI: local:///opt/flink/flink-on-k8s-demo-1.0-SNAPSHOT.jar
entryClass: org.fblinux.StreamWordCount
args:
parallelism: 1
upgradeMode: stateless
提交yaml:
kubectl apply -f application-deployment.yaml

web页面验证:
http://flink.k8s.io/flink/application-deployment/#/job/running
方式2:将作业jar包放到外部存储,通过pv方式挂载到flink pod,好处是由始至终只使用一个flink镜像即可,在实际应用中采用这种方式居多
(1)创建JAR包的PVC
[root@k8s-demo001 ~]# cat flink-jar-pvc.yaml
# Flink 作业jar 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-jar-pvc # jar pvc名称
namespace: flink
spec:
storageClassName: nfs-storage #sc名称
accessModes:
- ReadOnlyMany #采用ReadOnlyMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
[root@k8s-demo001 ~]# kubectl apply -f flink-jar-pvc.yaml
[root@k8s-demo001 ~]# kubectl get pvc -n flink
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
flink-jar-pvc Bound pvc-3a273170-a195-48dd-a100-016ee6980dc6 1Gi ROX nfs-storage 5h36m
2、将JAR包放到PV的实际路径
3、编写application-deployment-with-pv.yaml
[root@k8s-demo001 ~]# cat application-deployment-with-pv.yaml
# Flink Application集群
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: application-deployment-with-pv
spec:
image: flink:1.13.6
flinkVersion: v1_13
imagePullPolicy: IfNotPresent # 镜像拉取策略,本地没有则从仓库拉取
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io/{{namespace}}/{{name}}(/|$)(.*)"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/$2"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink
jobManager:
replicas: 1
resource:
memory: "1024m"
cpu: 1
taskManager:
replicas: 1
resource:
memory: "1024m"
cpu: 1
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- name: flink-jar # 挂载nfs上的jar
mountPath: /opt/flink/jar
volumes:
- name: flink-jar
persistentVolumeClaim:
claimName: flink-jar-pvc
job:
jarURI: local:///opt/flink/jar/flink-on-k8s-demo-1.0-SNAPSHOT.jar
entryClass: org.fblinux.StreamWordCount
args:
parallelism: 1
upgradeMode: stateless
提交yaml:
kubectl apply -f application-deployment-with-pv.yaml

web界面验证:
http://flink.k8s.io/flink/application-deployment-with-pv/#/overview
7.四种作业提交模式总结
1、Application模式和Session模式的选择
Application模式和Session模式两者最大区别在于集群的生命周期和资源管理隔离程度
| 模式 | 场景 |
|---|---|
| Application模式 | 对于核心、优先级高、高保障这类的作业,强力推荐使用Application模式,建议作为Flink运行模式的默认选项 |
| Session 模式 | 对保障性要求相对不高的,或者出于运维管理便利的考量,例如需要通过外部系统通过调用Flink Restful接口管理作业的提交和启停,可以考虑使用Session模式 |
2、Application 模式两种提交方式选择
Application模式的2种作业提交方式的最大区别在于是否需要将作业Jar包打入Flink镜像
| 方式 | 特点 |
|---|---|
| Jar包打进镜像 | (1)每个作业都要打一个镜像,容易导致镜像数量过多,不便于管理 (2)占用大量空间,1个Flink镜像约600M 不推荐 |
| Jar包通过PV挂载 | (1)Jar包不用打到镜像,省去镜像构建工作 (2)只需维护少量几个Flink基础镜像,节省空间 推荐此方式 |
3、Session模式2种提交方式选择
Session模式的2种作业提交方式的最大区别在于Jar包的获取方式
| 方式 | 特点 |
|---|---|
| Web上传方式 | (1)可以通过人工访问Flink UI页面上传Jar包和提交作业,操作灵活,便于调试 (2)也可以通过编写程序调用Flink Restful API上传Jar包和提交作业,可以灵活控制Flink作业更新和启停 |
| Http下载方式 | (1)可以统一将作业Jar包发布到HTTP文件服务器,例如tomcat、apache或nginx,实现作业Jar包的统一存放 (2)需要编写FlinkSessionJob yaml, (3)通过k8s的kubectl命令管理作业的更新和启停,这个也可以通过编写程序调用K8s API实现。 |
转载请注明:西门飞冰的博客 » (1)Flink on K8S 的简单实现



