1.Flink HistoryServer用途
HistoryServer可以在Flink 作业终止运行(Flink集群关闭)之后,还可以查询已完成作业的统计信息。此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
2.部署Flink HistoryServer
1、创建 flink historyserver pvc,保存Flink作业归档数据。
[root@k8s-demo001 ~]# cat flink-historyserver-pvc.yaml
#Flink Historyserver 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-historyserver-pvc # historyserver pvc名称
namespace: flink # 指定归属的名命空间
spec:
storageClassName: nfs-storage #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 1Gi #存储容量,根据实际需要更改
[root@k8s-demo001 ~]# kubectl apply -f flink-historyserver-pvc.yaml
2、配置flink historyserver,创建flink historyserver configmap
[root@k8s-demo001 ~]# cat flink-historyserver-conf.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: flink-historyserver-conf
namespace: flink
annotations:
kubesphere.io/creator: admin
data:
flink-conf.yaml: |
blob.server.port: 6124
kubernetes.jobmanager.annotations: flinkdeployment.flink.apache.org/generation:2
kubernetes.jobmanager.replicas: 1
kubernetes.jobmanager.cpu: 1.0
$internal.flink.version: v1_13
kubernetes.taskmanager.cpu: 1.0
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
kubernetes.service-account: flink
kubernetes.cluster-id: flink-historyserver
kubernetes.container.image: flink-hdfs:1.13.6
parallelism.default: 2
kubernetes.namespace: flink
taskmanager.numberOfTaskSlots: 2
kubernetes.rest-service.exposed.type: ClusterIP
kubernetes.operator.reconcile.interval: 15 s
kubernetes.operator.metrics.reporter.slf4j.interval: 5 MINUTE
kubernetes.operator.metrics.reporter.slf4j.factory.class: org.apache.flink.metrics.slf4j.Slf4jReporterFactory
jobmanager.memory.process.size: 1024m
taskmanager.memory.process.size: 1024m
kubernetes.internal.jobmanager.entrypoint.class: org.apache.flink.kubernetes.entrypoint.KubernetesSessionClusterEntrypoint
kubernetes.pod-template-file: /tmp/flink_op_generated_podTemplate_17272077926352838674.yaml
execution.target: kubernetes-session
jobmanager.archive.fs.dir: file:///opt/flink/flink_history
historyserver.archive.fs.dir: file:///opt/flink/flink_history
historyserver.archive.fs.refresh-interval: 10000
historyserver.web.port: 8082
web.tmpdir: /opt/flink/webupload
web.upload.dir: /opt/flink/webupload
web.cancel.enable: false
internal.cluster.execution-mode: NORMAL
queryable-state.proxy.ports: 6125
state.checkpoints.dir: file:///opt/flink/checkpoints
log4j.properties: |
# Allows this configuration to be modified at runtime. The file will be checked every 30 seconds.
monitorInterval=30
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.file.ref = MainAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO
# Log all infos in the given file
appender.main.name = MainAppender
appender.main.type = RollingFile
appender.main.append = true
appender.main.fileName = ${sys:log.file}
appender.main.filePattern = ${sys:log.file}.%i
appender.main.layout.type = PatternLayout
appender.main.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.main.policies.type = Policies
appender.main.policies.size.type = SizeBasedTriggeringPolicy
appender.main.policies.size.size = 100MB
appender.main.policies.startup.type = OnStartupTriggeringPolicy
appender.main.strategy.type = DefaultRolloverStrategy
appender.main.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
log4j-console.properties: |
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
# Flink Deployment Logging Overrides
# rootLogger.level = DEBUG
[root@k8s-demo001 ~]# kubectl apply -f flink-historyserver-conf.yaml
检查

3、创建Historyserver服务
[root@k8s-demo001 ~]# cat flink-historyserver.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: flink
labels:
app: flink-historyserver
name: flink-historyserver
name: flink-historyserver
spec:
replicas: 1
selector:
matchLabels:
name: flink-historyserver
template:
metadata:
namespace: flink
labels:
app: flink-historyserver
name: flink-historyserver
spec:
hostAliases: # hosts配置
- ip: "172.16.252.129"
hostnames:
- "Kafka-01"
- ip: "172.16.252.130"
hostnames:
- "Kafka-02"
- ip: "172.16.252.131"
hostnames:
- "Kafka-03"
containers:
- name: flink-historyserver
env:
- name: TZ
value: Asia/Shanghai
image: flink:1.13.6
command: [ 'sh','-c','/docker-entrypoint.sh history-server' ]
ports:
- containerPort: 8082
volumeMounts:
- name: flink-historyserver-conf
mountPath: /opt/flink/conf/flink-conf.yaml
subPath: flink-conf.yaml
- name: flink-historyserver-conf
mountPath: /opt/flink/conf/log4j.properties
subPath: log4j.properties
- name: flink-historyserver-conf
mountPath: /opt/flink/conf/log4j-console.properties
subPath: log4j-console.properties
- name: flink-historyserver
mountPath: /opt/flink/flink_history
volumes: # 挂载卷配置
- name: flink-historyserver-conf
configMap:
name: flink-historyserver-conf
- name: flink-historyserver
persistentVolumeClaim:
claimName: flink-historyserver-pvc
# ---
# kind: Service
# apiVersion: v1
# metadata:
# namespace: flink
# name: flink-historyserver
# spec:
# type: NodePort
# ports:
# - port: 8082
# nodePort: 31082
# selector:
# name: flink-historyserver
# ingress按实际情况配置
---
apiVersion: v1
kind: Service
metadata:
labels:
app: flink-historyserver
name: flink-historyserver
name: flink-historyserver
namespace: flink
spec:
selector:
app: flink-historyserver
ports:
- port: 8082
protocol: TCP
targetPort: 8082
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: flink
name: flink-historyserver
annotations:
nginx.ingress.kubernetes.io/default-backend: ingress-nginx-controller
nginx.ingress.kubernetes.io/use-regex: 'true'
spec:
ingressClassName: nginx
rules:
- host: "flink-hs.k8s.io"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: flink-historyserver
port:
number: 8082
[root@k8s-demo001 ~]# kubectl apply -f flink-historyserver.yaml
验证:

访问Flink UI:
3.提交flink作业
1、编写提交作业的yaml
这里需要挂在Historyserver的pvc,并配置Historyserver的归档路径到pvc挂载路径
[root@k8s-demo001 ~]# cat application-deployment-checkpoint-ha-hs.yaml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: application-deployment-checkpoint-ha-hs # flink 集群名称
spec:
image: flink:1.13.6 # flink基础镜像
flinkVersion: v1_13 # flink版本,选择1.13
imagePullPolicy: IfNotPresent # 镜像拉取策略,本地没有则从仓库拉取
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io/{{namespace}}/{{name}}(/|$)(.*)"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/$2"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
state.checkpoints.dir: file:///opt/flink/checkpoints
high-availability.type: kubernetes
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory # JobManager HA
high-availability.storageDir: file:///opt/flink/flink_recovery # JobManager HA数据保存路径
jobmanager.archive.fs.dir: file:///opt/flink/flink_history # JobManager 归档路径
historyserver.archive.fs.dir: file:///opt/flink/flink_history # Historyserver 归档路径
historyserver.archive.fs.refresh-interval: "10000" # Historyserver 文件刷新间隔
serviceAccount: flink
jobManager:
replicas: 2 # HA下, jobManger的副本数要大于1
resource:
memory: "1024m"
cpu: 1
taskManager:
resource:
memory: "1024m"
cpu: 1
podTemplate:
spec:
hostAliases:
- ip: "172.16.252.129"
hostnames:
- "Kafka-01"
- ip: "172.16.252.130"
hostnames:
- "Kafka-02"
- ip: "172.16.252.131"
hostnames:
- "Kafka-03"
containers:
- name: flink-main-container
env:
- name: TZ
value: Asia/Shanghai
volumeMounts:
- name: flink-jar # 挂载nfs上的jar
mountPath: /opt/flink/jar
- name: flink-checkpoints # 挂载checkpoint pvc
mountPath: /opt/flink/checkpoints
- name: flink-log # 挂载日志 pvc
mountPath: /opt/flink/log
- name: flink-ha # HA pvc配置
mountPath: /opt/flink/flink_recovery
- name: flink-historyserver
mountPath: /opt/flink/flink_history
volumes:
- name: flink-jar
persistentVolumeClaim:
claimName: flink-jar-pvc
- name: flink-checkpoints
persistentVolumeClaim:
claimName: flink-checkpoint-application-pvc
- name: flink-log
persistentVolumeClaim:
claimName: flink-log-pvc
- name: flink-ha
persistentVolumeClaim:
claimName: flink-ha-pvc
- name: flink-historyserver
persistentVolumeClaim:
claimName: flink-historyserver-pvc
job:
jarURI: local:///opt/flink/jar/flink-on-k8s-demo-1.0-SNAPSHOT-jar-with-dependencies.jar # 使用pv方式挂载jar包
entryClass: org.fblinux.StreamWordCountWithCP
args: # 传递到作业main方法的参数
- "172.16.252.129:9092,172.16.252.130:9092,172.16.252.131:9092"
- "flink_test"
- "172.16.252.113"
- "3306"
- "flink_test"
- "wc"
- "file:///opt/flink/checkpoints"
- "10000"
- "1"
parallelism: 1
upgradeMode: stateless
[root@k8s-demo001 ~]# kubectl apply -f application-deployment-checkpoint-ha-hs.yaml
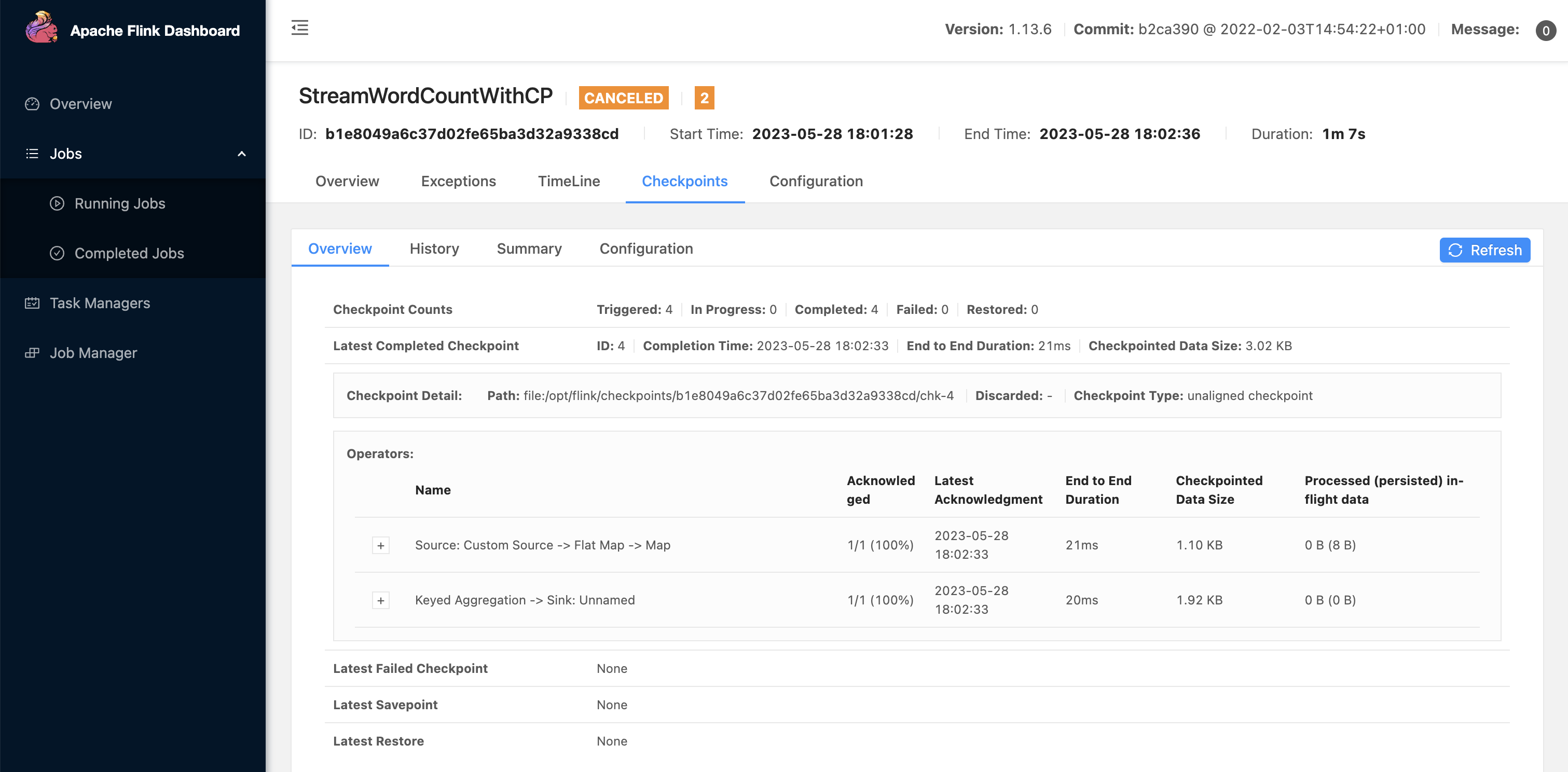
作业提交之后,可以手动往Kafka 写入一些数据,然后关闭作业
转载请注明:西门飞冰的博客 » (5)Flink on k8s之historyServer



