1.CCA介绍
Cloudera Certified Associate(CCA认证)是Cloudera面向初中级 Hadoop技术人员推出的认证考试。由于Cloudera的Hadoop发行版是目前 使用最广泛的版本,Cloudera的认证也因此被广泛承认。能够获得这类 证书对于技术人员求职、企业投标等都是有重要作用的。
CCA认证又分为以下三个方向:
CCA Spark and Hadoop Developer:学会使用Apache Spark和其他 Cloudera企业级工具,实现对大数据的集成、转换、处理。
CCA Data Analyst:学会对原始数据进行加载、转换、清洗、建模,从 而定义数据间的关系并抽取出有意义的结果。
CCA Administrator:学会针对部署Cloudera Hadoop发行版的企业进行 核心系统和集群运维的技能。
本文会以CCA Administrator考试中的集群配置、扩容、升级、高可用、故障排除,常用操作等20个实例来进行分享,帮助大家快速掌握CDH的使用
2.案例一
描述:某个集群的使用者需要通过客户端登录集群,请使用CM下载HDFS 和YARN的配置文件,保存到客户端机器的/home/cert/problem1目录下, 并保持文件名不变。
操作流程:
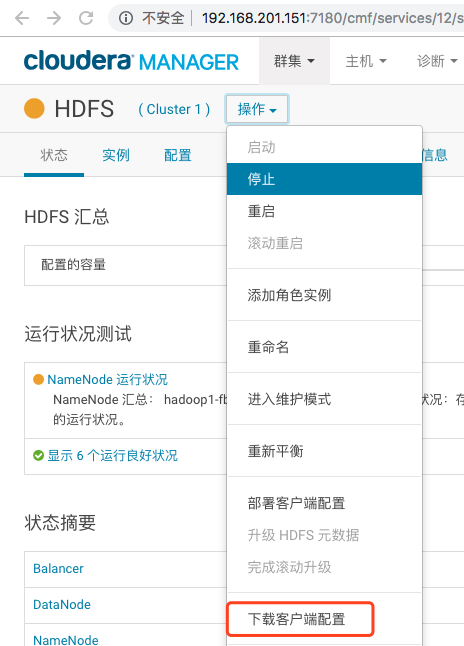
登陆CM界面,选择HDFS服务,点击操作下载客户端配置,将下载的文件移动到客户端机器的/home/cert/problem1目录下
3.案例二
描述:根据管理要求,需要限制HDFS服务的日志大小。其限制为, NameNode服务保留4个日志文件,总量不超过8GB;Secondary NameNode 服务也保留4个日志文件,总量不超过8GB;两个服务总占用的磁盘空间 量不超过16GB
解答:根据简单计算,单个服务的单个日志只要不超 过2GB,并将日志数设为4个,即可以满足要求。
操作流程:
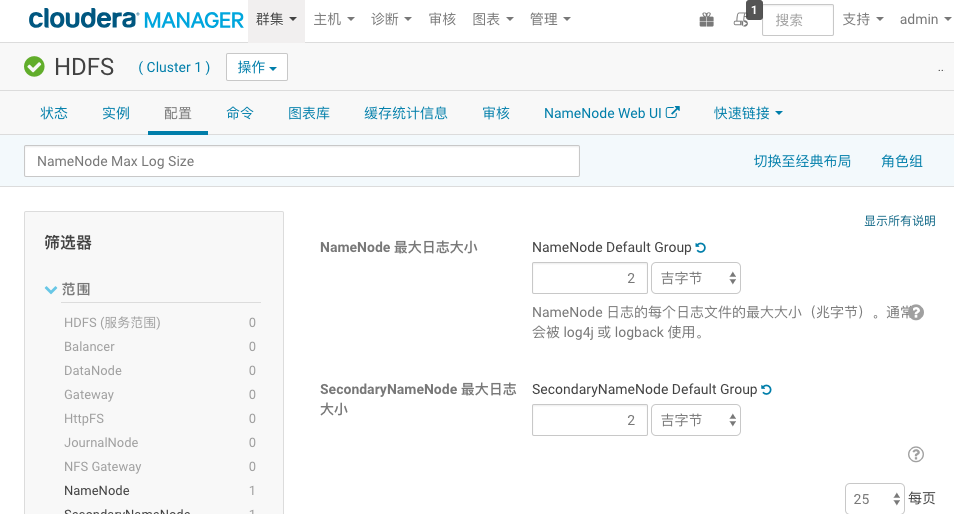
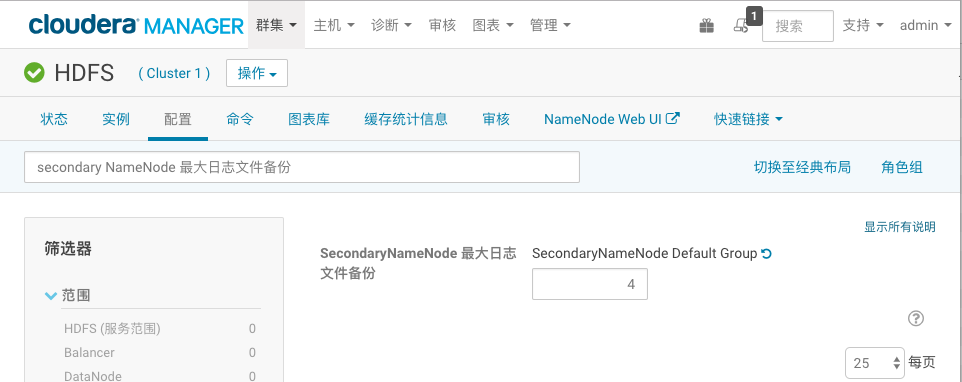
(1)登陆CM界面,选择HDFS服务,点击配置,搜索“NameNode Max Log Size”设置namenode和secondary最大日志大小为2G
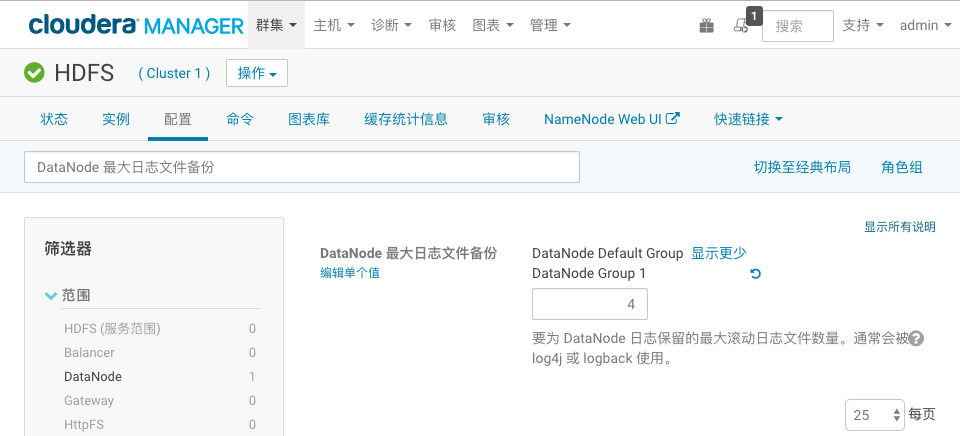
(2)分别搜索“DataNode 最大日志文件备份”和“secondary NameNode 最大日志文件备份”并设置值为4
4.案例三
描述:集群承接了日志分析需求,将保存百万、千万数量级的文件,因此需要扩大NameNode使用的堆内存,使其可以管理尽可能多的文件。物理内存的分配要求为:节点总物理内存为31GB,为系统服务保留的内存 为6.2GB;NameNode和Secondary NameNode需设置相等大小的堆内存; 所有服务的堆内存均需要除以1.3后计入总使用量中。需要为NameNode 和相关服务配置尽可能大且满足要求的内存量,且不能触发任何警告。
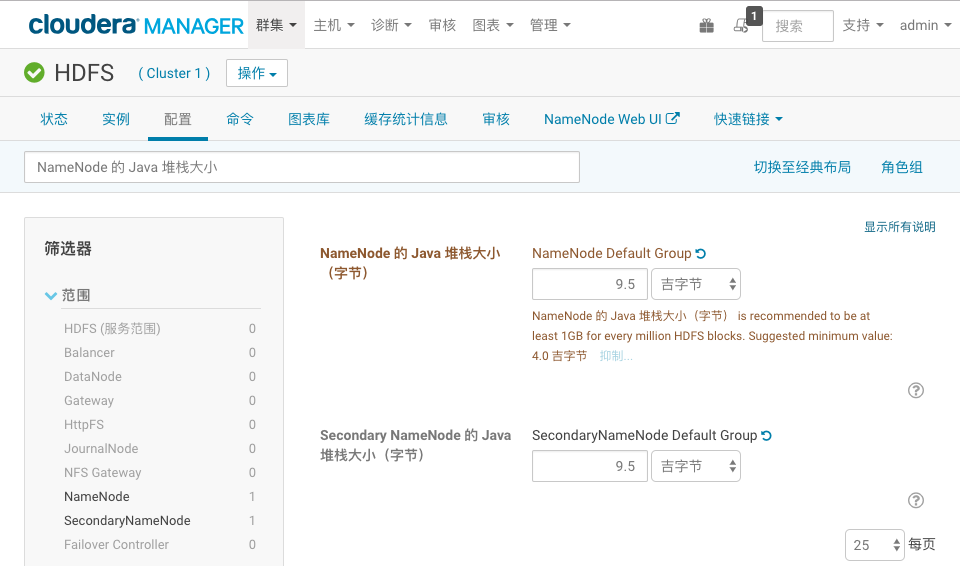
解答:根据计算(31 – 6.2) / 1.3 = 19,因此 NameNode和Secondary NameNode各可设置9.5GB的堆内存。
操作流程:登陆CM界面,选择HDFS服务,点击“配置“,搜索“NameNode 的 Java 堆栈大小”,分别设置NameNode和secondary Namenode的堆大小为9.5G,设置完成后重启HDFS服务。
5.案例四
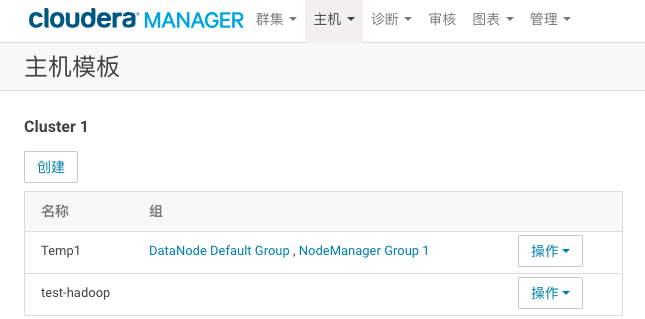
描述:公司新购了一批机器,准备扩充DataNode节点。你决定使用host template功能来为新机器配置DataNode通用的服务。新节点需要作为 HDFS和YARN的工作节点,因此模版的设计如下:
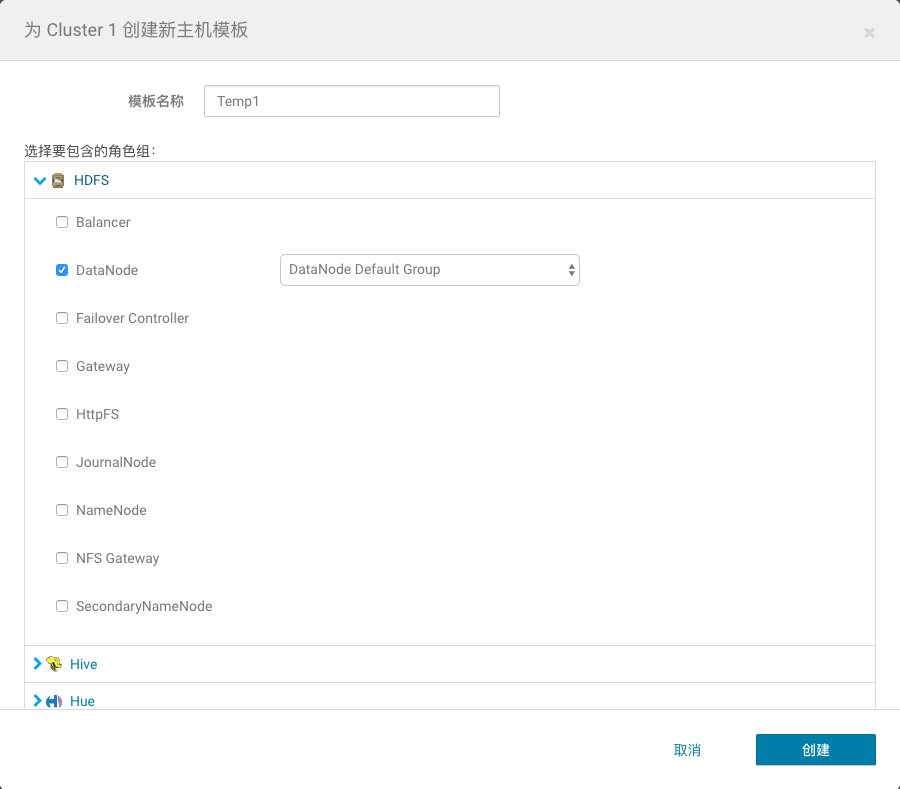
名称: Temp1
HDFS roles:DataNode
YARN roles:NodeManager 要求需要套用HDFS和YARN的Default Group的配置。
考点:在企业级实战中,集群扩容是常见且重要的 操作,如果手工一台一台操作,不仅效率低下,而且容易出错。CM 供 了多种机制来简化扩容操作,其中host template就是其中重要的一种, 通过该特性,可以大大简化工作节点的配置(对于管理节点、工具节点、 边缘节点,如果有多台配置完全一样,也可以使用该特性来扩容),如 DataNode,NodeManager,Kafka Broker等。
操作流程:
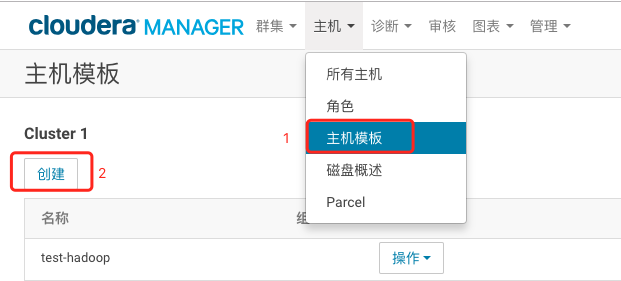
1、点击CM页面最上方的“主机”–> “主机模版”–>点击创建
2、输入模板名称,并根据要求选择角色,最后点击create保存
创建完成如下所示
6.案例五
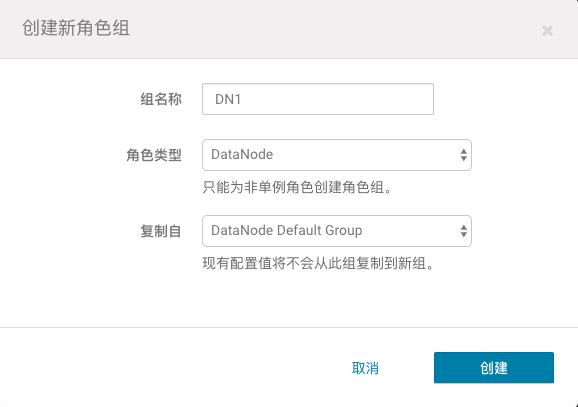
描述:公司新购了一批机器,准备扩充DataNode节点。然而,新机器的 硬件配置和旧机器有一些差异。你决定为旧机器创建一个角色组,设置 合适的配置。新机器继续使用默认的角色组(Default Group)的配置, 就如前面我们配置的模版一样。新角色组的需求为,命名为DN1,先继 承默认的角色组的配置,并使旧机器套用DN1的配置。然后要变更一些 参数,DN1和Default Group的DataNode Volume Choosing Policy参数 都必需设置为Avaliable Space。Default Group的Available Space Policy Balanced Preference参数需要设置为0.85,DN1的Available Space Policy Balanced Preference参数需要设置为0.8。
操作流程:
1、选择HDFS服务,点击配置,点击右上的“角色组”,点击“创建”,输入指定的group name,然后选择从哪个角色组复制,最后点击创建。
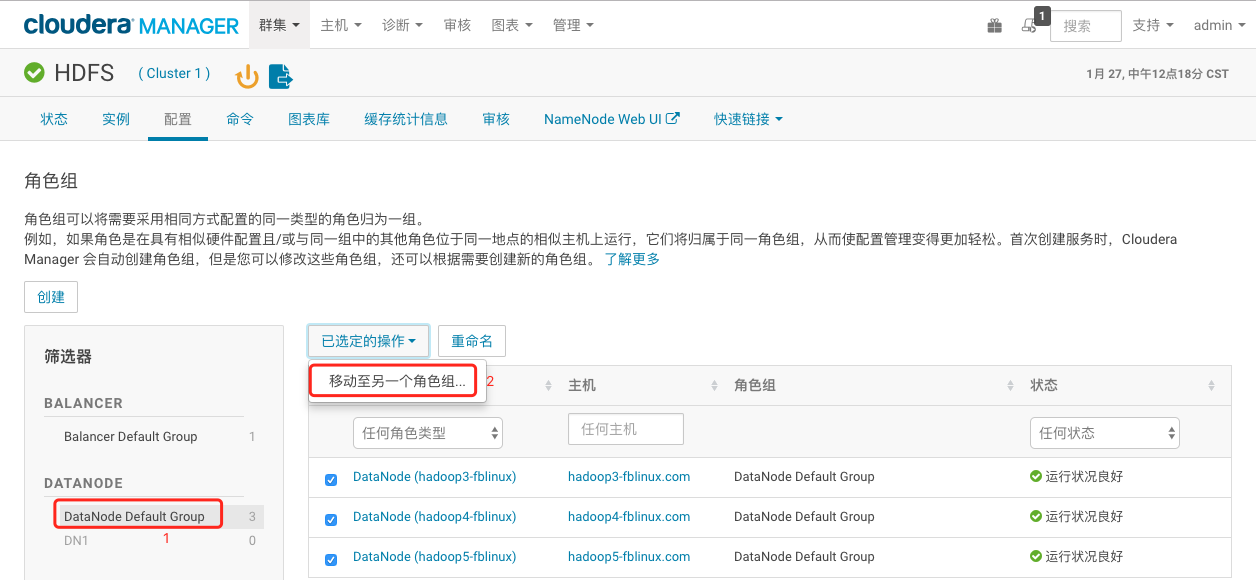
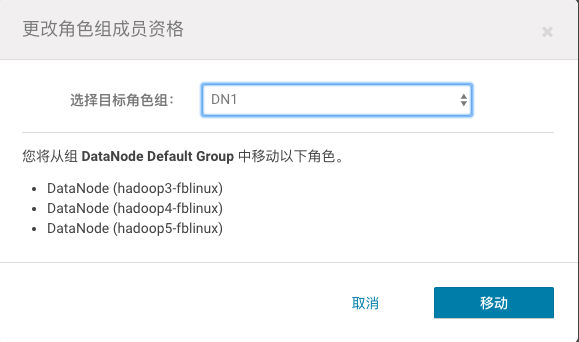
2、点击左侧的DateNode Default Group这个组,全选所有节点,点击“已选定的操作”,点击“移动到另一个角色组”,选中DN1, 并Move。
3、回到配置页面,搜索”DataNode Volume Choosing Policy”,改为“可用空间”,保存。
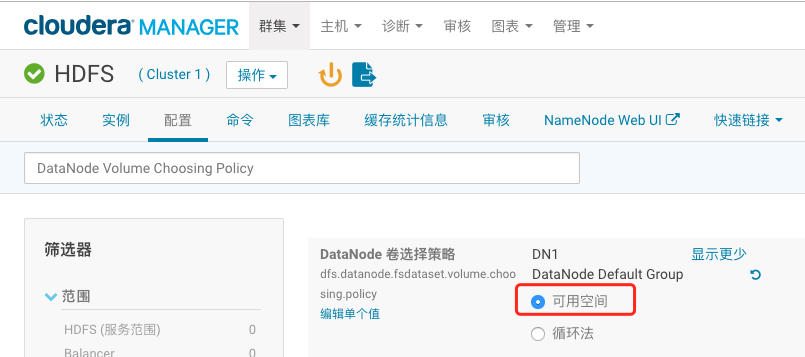
4、搜索”Available Space Policy Balanced Preference”,点击属性名下 方的编辑单个值,将DN1的这一项改为0.8,DateNode Default Group的这一项改为0.85,保存。

5、点击集群名右侧的小箭头,“部署客户端配置”,然后重启 集群。
7.案例六
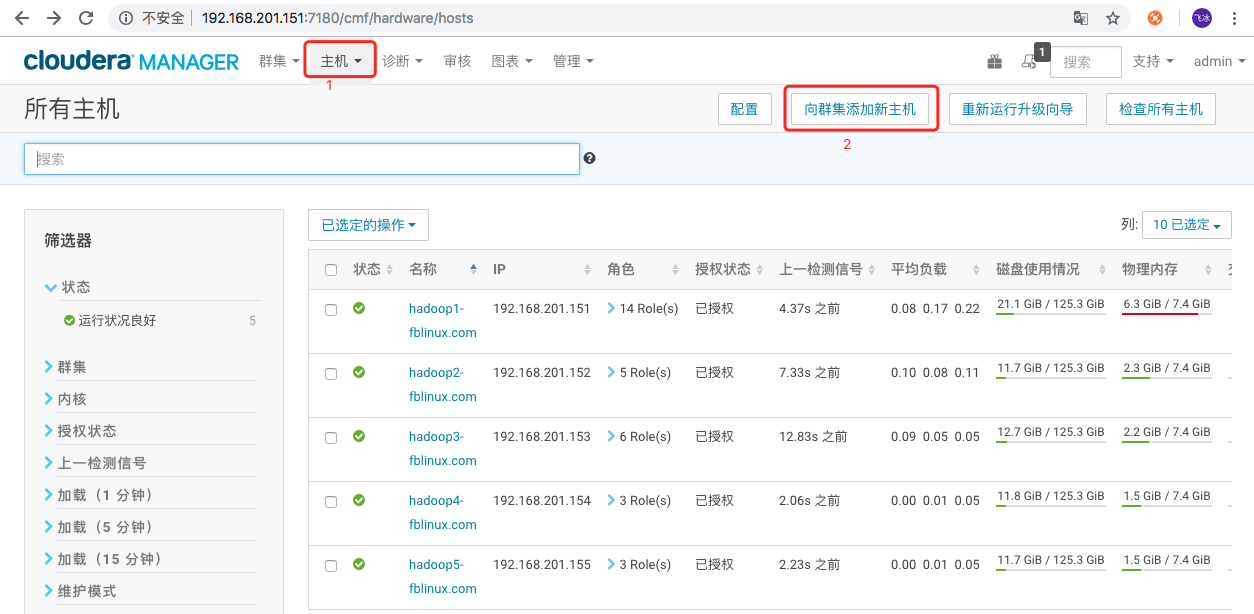
描述:正式地来将新节点加入集群。我们需要将hadoop6这个节点加入 CM的托管,并套用Temp1这个host template从而加入集群。
操作流程:
1、点击“主机” -“添加新主机到集群”,根据向导,搜索主机名 hadoop6.fblinux.com并选中,接下去的步骤和集群初始安装时基本一致,直到全部完成。
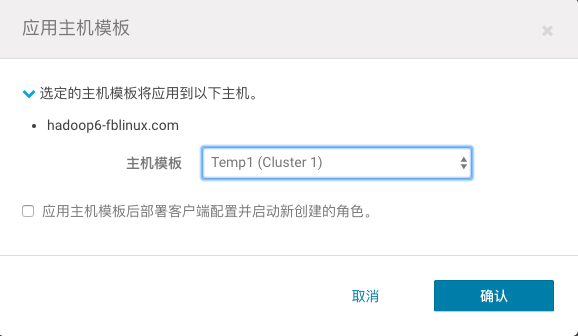
2、回到Hosts界面,选中hadoop6节点,点击已选定的操作-应用主机模板,选中Temp1,并打上勾,Confirm。全部执行完后, 该节点即具备DataNode和NodeManager的功能。

3、点击集群名右侧的小箭头,Deploy Client Configuration,然后重启集群。
8.案例七
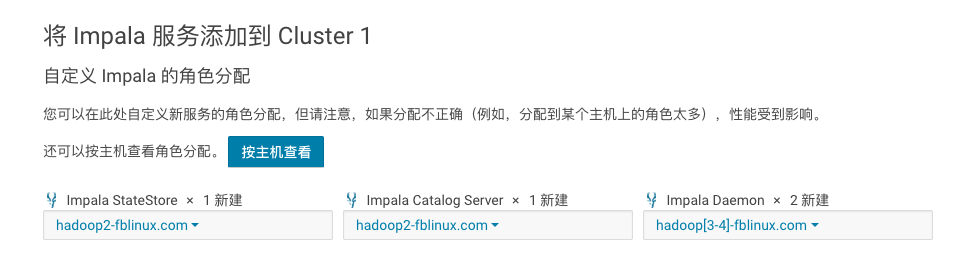
描述:公司的数据分析师过去使用hive进行数据分析,由于impala的速度比hive更快,这些分析师很感兴趣,想在工作中使用这些组件。请你按照指定的要求来安装impala:Catalog Server和StateStore安装在Hadoop2上,impala Daemons安装在hadoop3和Hadoop4上。
操作流程:
1、在CM主界面集群选项中,点击“添加服务”即可,然后选择impala服务,选择对应的节点安装即可。
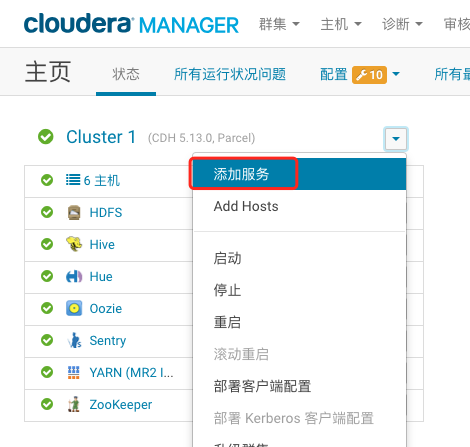
2、根据要求,选择安装的节点即可
9.案例八
描述:公司希望采用Kafka作为消息队列,需要你在当前集群中部署 Kafka服务。然而,之前有另一个管理员尝试部署Kafka但失败了。请部署Kafka,并解决安装过程中遇到的各种问题。
Kafka节点分配如下,Kafka Broker安装在hadoop5和hadoop6上,Gateway 安装在hadoop5上。
提示:如果没有干净卸载Kafka并再次安装,会出现”mismatched broker ID”的错误提示,可修改log.dirs参数并重启Kafka服务解决。
操作流程:
1、点击首页顶部的“主机”- “Parcels”
2、如果没有配置Kafka的源,需要加入源地址(http:// archive.cloudera.com/kafka/parcels/latest/),然后依次执行下载、分发、激活
(1)指定Kafka按照源,Kafka默认没有在CDH的安装中

(2)指定完成Kafka的源之后,在指定的parcel后面点击下载就可以开始下载Kafka的安装程序了

(3)下载完成之后点击分配,激活即可安装Kafka程序
3、回到首页,点击集群右侧的小箭头,添加服务,选择Kafka,根据要求选择节点,并完成服务的安装,如果遇到提示的错误,修过log.dirs参数即可。

10.案例九
描述:公司的数据分析师希望将一些数据从关系型数据库中导入Hive用于查询。你知道Sqoop组件可以完成该任务,但目前集群上没有。具体需求为:源数据为mysql中lesson库的student表,需要导入到Hive中 question9库的student表,并尽可能不改变数据类型。Sqoop Gateway 安装在hadoop3上。
准备内容:mysql数据库创建相关表并插入数据。
mysql> select * from student; +-------+----------+------------+----------+ | ID | name | dept_name | tot_cred | +-------+----------+------------+----------+ | 00128 | Zhang | Comp. Sci. | 102 | | 12345 | Shankar | Comp. Sci. | 32 | | 19991 | Brandt | History | 80 | | 23121 | Chavez | Finance | 110 | | 44553 | Peltier | Physics | 56 | | 45678 | Levy | Physics | 46 | | 54321 | Williams | Comp. Sci. | 54 | | 55739 | Sanchez | Music | 38 | | 70557 | Snow | Physics | 0 | | 76543 | Brown | Comp. Sci. | 58 | | 76653 | Aoi | Elec. Eng. | 60 | | 98765 | Bourikas | Elec. Eng. | 98 | | 98988 | Tanaka | Biology | 120 | +-------+----------+------------+----------+
操作流程:
1、点击集群名右侧的小箭头,添加服务,安装Sqoop服务。
2、在hive中创建所需的库和表
hive> create database question9;
OK
Time taken: 2.499 seconds
hive> use question9;
hive> create table student(
> id string,
> name string,
> dept_name string,
> tot_cred decimal(3,0)
> )
> row format delimited fields terminated by '\t' lines terminated by '\n'
> stored as textfile;
OK
Time taken: 0.8 seconds
3、使用sqoop命令导入
[hdfs@hadoop3-fblinux ~]# sqoop import \ > --connect jdbc:mysql://192.168.201.151:3306/lesson \ > --username sqoop \ > --password '!QAZ2wsx' \ > --table student \ > --fields-terminated-by '\t' \ > --delete-target-dir \ > --num-mappers 1 \ > --hive-import \ > --hive-database question9 \ > --hive-table student
4、hive 下验证数据

11.案例十
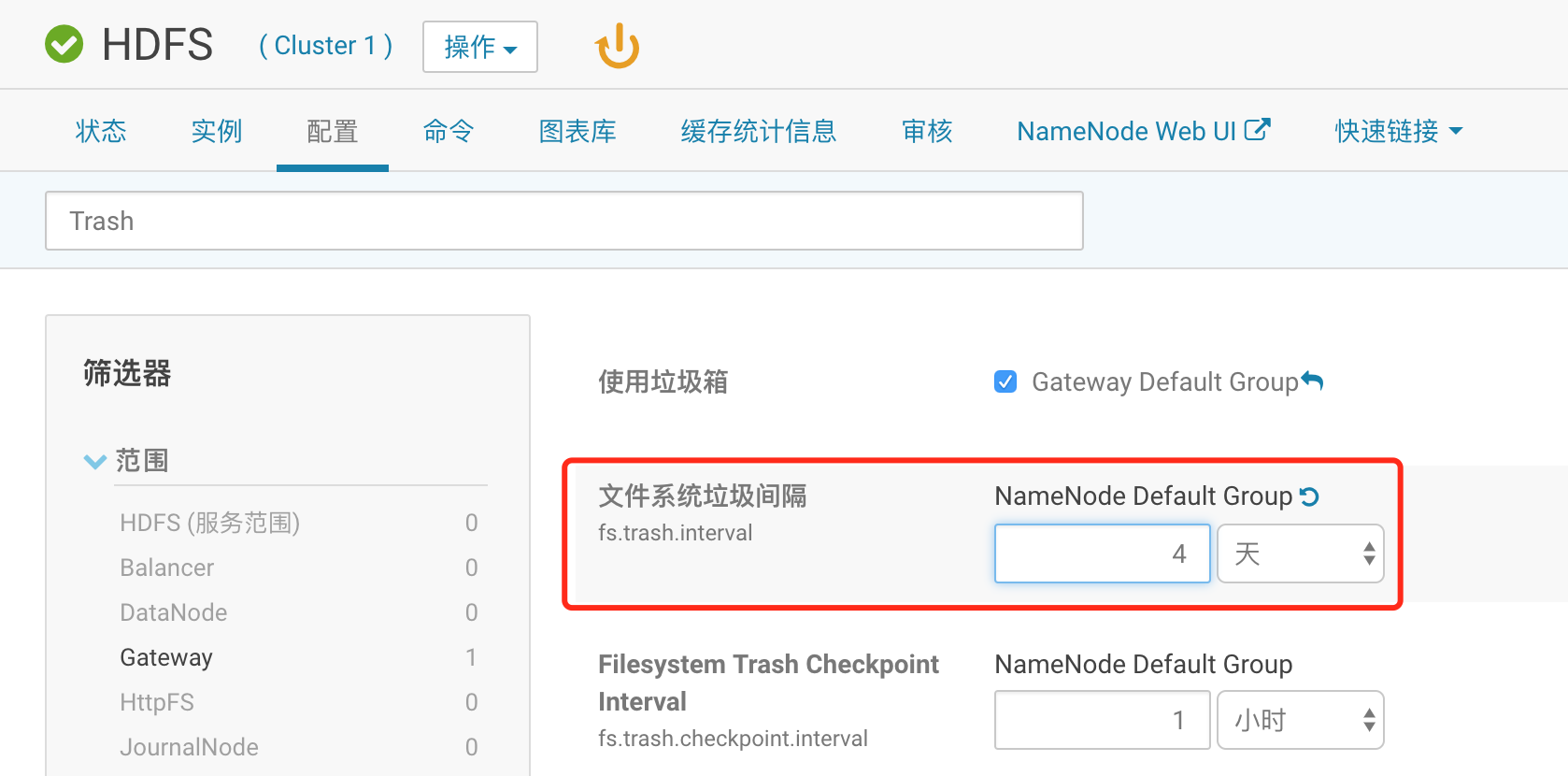
描述:在讨论公司的运维策略时,有人如果误删了HDFS的文件,可能几天都不会发现,尤其是当周末前发生这样的情况时。为了提供足够的保护级别,你决定将HDFS数据删除后永久清除的时间改为4天。
操作流程:
点击hdfs,配置,搜索“Trash”设置为4day,确保“使用垃圾箱”,勾选,然后重启hdfs服务
转载请注明:西门飞冰的博客 » CDH 20个实战案例